Coding Convention¶
Objectives of the Convention¶
- µSpectre is a collaborative project and these coding conventions aim to make reading and understanding its code as pain-free as possible, while ensuring the four main requirements of the library
Versatility
Efficiency
Reliability
Ease-of-use
Versatility requires that the core of the code, i.e., the data structures and fundamental algorithms be written in a generic fashion. The genericity cannot come at the cost of the second requirement – Efficiency – which is the reason why the material base classes make extensive use of template metaprogramming and expression templates. Reliability can only be enforced through good unit testing with high test coverage, and ease-of-use relies on a good documentation for developers and users alike.
Review of submitted code is the main mechanism to enforce the coding conventions.
Structure¶
This section contains planned features that are not yet implemented, but that need to be considered during the development effort.
The goal of this section is to define a maintainable and testable architecture for µSpectre. In order to achieve this, the software is segmented in modules that perform one testable task each and are linked through well defined interfaces. This way, when the implementation of a module changes, the other modules do not need to be adapted, as long as the interfaces are respected. In the case of µSpectre, the central task is the evaluation of RVEs, referred to as the core library, and there are the different language bindings, and the FEM plugins. This segmentation to obtain maintainability and testability follows the Don’t repeat yourself! (DRY) principle stated as “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system” by Hunt (2000): Since all algorithms and procedures are implemented only once and only in the core library, there is only one unit test per feature to implement and maintain. Unit tests for the language bindings do not need to retest these features and test merely correct wrapping and proper memory management. An exception to this rule are tests that are more convenient to implement in any of the bound languages rather than in a C++ test (e.g. the FFT module is tested in python against numpy.fft as reference.
Figure 1 shows a schematic of the projected structure and identifies a chain of three modules, where each new module depends on the previous one.
The first module contains only existing external (third-party) FFT implementations and is not part of the development effort for this project. The block is listed for clarity since the choices made here determine the type of machines the final code can run on.
The second module consists of i) the core library, which encapsulates the implementation of the spectral homogenisation method and represents the major projected development and maintenance effort, as well as ii) a set of language bindings. This second module allows single-scale RVE computations directly in most of the popular computing environments. It furthermore allows to rapidly prototype a simulation in a convenient interactive environment such as Jupyter or Matlab, and scale it up to a computing cluster when necessary using the same software.
The third and last module is a collection of plugins for multiple open-source and commercial FEM codes and provides coupled concurrent multiscale computation capabilities in the spirit of FE².
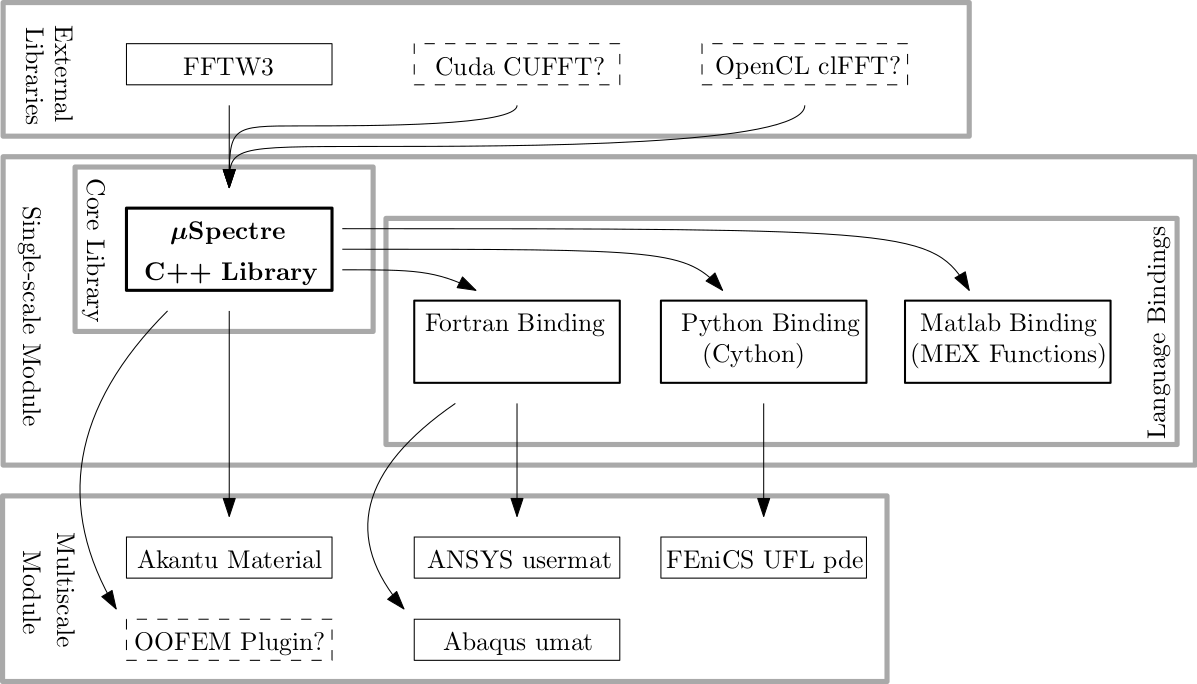
Figure 1: Principal modules of the platform. Boxes with dashed lines mark optional modules. External libraries refer to established and well-tested existing third-party FFT implementations. The core library µSpectre represents the main development objective of this project and will be written in modern C++14 and wrapped in language bindings for Fortran, Python, and Matlab in order to be usable for single-scale computations by most researchers in their favourite computing environment. Plugins for multiple open-source and commercial FEM codes will use either the core library directly (Akantu, OOFEM), the Fortran language binding (ANSYS, Abaqus), or the Python language binding (FEniCS).¶
Documentation¶
There are two types of Documentation for µSpectre: on the one hand, there is this monograph which is supposed to serve as reference manual to understand, and use the library and its extensions, and to look up APIs and data structures. On the other hand, there is in-code documentation helping the developer to understand the role of functions, variables, member (function)s and steps in algorithms.
The in-code documentation uses the syntax of the doxygen documentation generator, as its lightweight markup language is very readable in the code and allows to generate the standalone API documentation in Reference.
All lengthier, text-based documentation is written for Sphinx in reStructuredText. This allows to write longer, more expressive texts, such as this convention or the Tutorials.
Testing¶
Every feature in µSpectre’s core library is supposed to be unit tested, and a missing test is considered a bug. Core library features are unit tested in the C++ unit tests (preferred option) or the python unit tests (both within the tests folder), because external contributors should not be expected to compile all the language bindings.
The unit tests typically use the Boost unit test framework to define C++ test cases and python’s unittest module for python tests. If necessary, standalone tests can be added by contributors, provided that they are added as ctest targets to the project’s main CMake file. See in the tests folder for examples regarding the tests.
C++ Coding Style and Convention¶
These are heavily inspired by the Google C++ Style Guide but are not compatible with it. These guidelines mostly establish a common vocabulary to write common code and do not give advice for efficient programming practices. For that, follow Scott Meyers book Effective Modern C++. As far as possible, the guidelines given in that book are also enforced by the -Weffc++ compile flag.
The goals of this style guide are:
- Style rules should pull their weight
The benefit of a style rule must be large enough to justify asking all of our engineers to remember it. The benefit is measured relative to the code base we would get without the rule, so a rule against a very harmful practice may still have a small benefit if people are unlikely to do it anyway. This principle mostly explains the rules we don’t have, rather than the rules we do: for example,
gotocontravenes many of the following principles, but is already vanishingly rare, so the Style Guide doesn’t discuss it.- Optimise for the reader, not the writer
Our core library (and most individual components submitted to it) is expected to continue for quite some time, and we will hopefully attract more external contributors. As a result, more time will be spent reading most of our code than writing it. We explicitly choose to optimise for the experience of our average contributor reading, maintaining, and debugging code in our code base rather than ease when writing said code. “Leave a trace for the reader” is a particularly common sub-point of this principle: When something surprising or unusual is happening in a snippet of code (for example, use of raw pointers in the
FFTEngineclasses), leaving textual hints for the reader at the point of use is valuable. Use explicit traces of ownership of objects on the heap using smart pointers such asstd::unique_ptrandstd::shared_ptr.- Be consistent with existing code
Using one style consistently through our code base lets us focus on other (more important) issues. Consistency also allows for automation: tools that format your code or adjust your
#includesonly work properly when your code is consistent with the expectations of the tooling. In many cases, rules that are attributed to “Be Consistent” boil down to “Just pick one and stop worrying about it”; the potential value of allowing flexibility on these points is outweighed by the cost of having people argue over them.- Be consistent with the broader C++ community when appropriate
Consistency with the way other organisations use C++ has value for the same reasons as consistency within our code base. If a feature in the C++ standard solves a problem, or if some idiom is widely known and accepted, that’s an argument for using it. However, sometimes standard features and idioms are flawed, or were just designed without our efficiency needs in mind. In those cases (as described below) it’s appropriate to constrain or ban standard features.
- Avoid surprising or dangerous constructs
C++ has features that are more surprising or dangerous than one might think at a glance. Some style guide restrictions are in place to prevent falling into these pitfalls. There is a high bar for style guide waivers on such restrictions, because waiving such rules often directly risks compromising program correctness.
- Avoid constructs that our average C++ programmer would find tricky or hard to maintain in the constitutive laws and solvers
C++ has features that may not be generally appropriate because of the complexity they introduce to the code. In the core library, where we make heavy use of template metaprogramming and expression templates for efficiency, it is totally fine to use trickier language constructs, because any benefits of more complex implementation are multiplied widely by usage, and the cost in understanding the complexity does not need to be paid by the average contributor who writes a new material or solver. When in doubt, waivers to rules of this type can be sought by starting an issue.
- Concede to optimisation when necessary
Performance is the overwhelming priority in the core library (i.e., data structures and low level algorithms that the typical user relies on often, but rarely uses directly). If performance optimisation is in conflict with other principles in this document, optimise.
Header Files¶
In general, every .cc file should have an associated .hh file. There are some common exceptions, such as unit tests and small .cc files containing just a main() function (e.g., see in the bin folder).
Correct use of header files can make a huge difference to the readability, size and performance of your code.
The following rules will guide you through the various pitfalls of using header files.
Self-contained Headers¶
Header files should be self-contained (compile on their own) and end in .hh. There should not be any non-header files that are meant for inclusion.
All header files should be self-contained. Users and refactoring tools should not have to adhere to special conditions to include the header. Specifically, a header should have header guards and include all other headers it needs.
Prefer placing the definitions for inline functions in the same file as their declarations. The definitions of these constructs must be included into every .cc file that uses them, or the program may fail to link in some build configurations. If declarations and definitions are in different files, including the former should transitively include the latter. Do not move these definitions to separately included header files (-inl.hh); this practice was common in the past, but is no longer allowed.
As an exception, a template that is explicitly instantiated for all relevant sets of template arguments, or that is a private implementation detail of a class, is allowed to be defined in the one and only .cc file that instantiates the template, see material_linear_elastic1.cc for an example.
The #define Guard¶
All header files should have #define guards to prevent multiple inclusion. The format of the symbol name should be CLASS_NAME_H (all caps with underscores), where ClassName (CamelCase) is the main class declared it the header file.
Make sure to use unique file names to avoid triggering the wrong #define guard.
Forward Declarations¶
Use forward declarations of µSpectre entities where it avoids includes and saves compile time.
A “forward declaration” is a declaration of a class, function, or template without an associated definition.
- Pros:
Forward declarations can save compile time, as
#includes force the compiler to open more files and process more input.Forward declarations can save on unnecessary recompilation.
#includes can force your code to be recompiled more often, due to unrelated changes in the header.
- Cons:
Forward declarations can hide a dependency, allowing user code to skip necessary recompilation when headers change.
A forward declaration may be broken by subsequent changes to the library. Forward declarations of functions and templates can prevent the header owners from making otherwise-compatible changes to their APIs, such as widening a parameter type, adding a template parameter with a default value, or migrating to a new namespace.
Forward declaring symbols from namespace std:: yields undefined behaviour.
It can be difficult to determine whether a forward declaration or a full
#includeis needed. Replacing an#includewith a forward declaration can silently change the meaning of code:// b.hh: struct B {}; struct D : B {}; // good_user.cc: #include "b.hh" void f(B*); void f(void*); void test(D* x) { f(x); } // calls f(B*)
If the #include was replaced with forward declarations for
BandD,test()would callf(void*).Forward declaring multiple symbols from a header can be more verbose than simply
#includeing the header.
Try to avoid forward declarations of entities defined in another project.
Inline Functions¶
Use inline functions for performance-critical code. Also, templated member functions that that cannot be explicitly instantiated need to be declared inline.
Names and Order of Includes¶
All of a project’s header files should be listed as descendants of the project’s source directory without use of UNIX directory shortcuts . (the current directory) or .. (the parent directory). For example, muSpectre/src/common/ccoord_operations.hh should be included as:
#include <libmugrid/ccoord_operations.hh>
- Use the following order for includes to avoid hidden dependencies:
µSpectre headers
A blank line
Other libraries’ headers
A blank line
C++ system headers
With this ordering, if a µSpectre header omits any necessary includes, the build will break. Thus, this rule ensures that build breaks show up first for the people working on these files, not for innocent people in different places.
You should include all the headers that define the symbols you rely upon, except in the case of forward declaration. If you rely on symbols from bar.hh, don’t count on the fact that you included foo.hh which (currently) includes bar.hh: include bar.hh yourself, unless foo.hh explicitly demonstrates its intent to provide you the symbols of bar.hh. However, any includes present in the related header do not need to be included again in the related .cc (i.e., foo.cc can rely on foo.hh’s includes).
Scoping¶
Namespaces¶
With few exceptions, place code in the namespace muSpectre. All other (subordinate) namespaces should have unique, expressive names based on their purpose. Do not use using-directives (e.g. using namespace foo) within the core library (but feel free to do so in the executables in the bin folder). Do not use inline namespaces. For unnamed namespaces, see Unnamed Namespaces and Static Variables.
- Definition:
Namespaces subdivide the global scope into distinct, named scopes, and so are useful for preventing name collisions in the global scope.
- Pros:
Namespaces provide a method for preventing name conflicts in large programs while allowing most code to use reasonably short names.
For example, if two different projects have a class
Fooin the global scope, these symbols may collide at compile time or at runtime. If each project places their code in a namespace,project1::Fooandproject2::Fooare now distinct symbols that do not collide, and code within each project’s namespace can continue to refer to Foo without the prefix.Inline namespaces automatically place their names in the enclosing scope. Consider the following snippet, for example:
namespace outer { inline namespace inner { void foo(); } // namespace inner } // namespace outer
The expressions
outer::inner::foo()andouter::foo()are interchangeable. Inline namespaces are primarily intended for ABI compatibility across versions.
- Cons:
Inline namespaces, in particular, can be confusing because names aren’t actually restricted to the namespace where they are declared. They are only useful as part of some larger versioning policy.
In some contexts, it’s necessary to repeatedly refer to symbols by their fully-qualified names. For deeply-nested namespaces, this can add a lot of clutter.
- Decision:
Namespaces should be used as follows:
Follow the rules on Namespace Names.
Terminate namespaces with comments as shown in the given examples.
Namespaces wrap the entire source file after includes and forward declarations of classes from other namespaces.
// In the .hh file namespace mynamespace { // All declarations are within the namespace scope. // Notice the lack of indentation. class MyClass { public: ... void Foo(); }; } // namespace mynamespace // In the .cc file namespace mynamespace { // Definition of functions is within scope of the namespace. void MyClass::Foo() { ... } } // namespace mynamespace
More complex
.ccfiles might have additional details, using-declarations.#include "a.h" namespace mynamespace { using ::foo::bar; ...code for mynamespace... // Code goes against the left margin. } // namespace mynamespace
Do not declare anything in namespace
std, including forward declarations of standard library classes. Declaring entities in namespacestdis undefined behaviour, i.e., not portable. To declare entities from the standard library, include the appropriate header file.You may not use a using-directive to make all names from a namespace available (namespace clobbering).
// Forbidden -- This pollutes the namespace. using namespace foo;
Do not use namespace aliases at namespace scope in header files except in explicitly marked internal-only namespaces, because anything imported into a namespace in a header file becomes part of the public API exported by that file.
// Shorten access to some commonly used names in .cc files. namespace baz = ::foo::bar::baz; // Shorten access to some commonly used names (in a .h file). namespace librarian { namespace impl { // Internal, not part of the API. namespace sidetable = ::pipeline_diagnostics::sidetable; } // namespace impl inline void my_inline_function() { // namespace alias local to a function (or method). namespace baz = ::foo::bar::baz; ... } } // namespace librarian
Do not use inline namespaces.
Unnamed Namespaces and Static Variables¶
When definitions in a .cc file do not need to be referenced outside that file, place them in an unnamed namespace or declare them static. Do not use either of these constructs in .hh files.
All declarations can be given internal linkage by placing them in unnamed namespaces. Functions and variables can also be given internal linkage by declaring them static. This means that anything you’re declaring can’t be accessed from another file. If a different file declares something with the same name, then the two entities are completely independent.
Use of internal linkage in .cc files is encouraged for all code that does not need to be referenced elsewhere. Do not use internal linkage in .hh files.
Format unnamed namespaces like named namespaces. In the terminating comment, leave the namespace name empty:
namespace {
...
} // namespace
Nonmember, Static Member, and Global Functions¶
Prefer placing nonmember functions in a namespace; use completely global functions rarely. Note: placing functions in a namespace keeps them globally accessible, the goal of this is not to suppress the use of non-member functions but rather to avoid polluting the global and muSpectre namespace by grouping them together in thematic namespaces, see for instance the namespace MatTB in materials/materials_toolbox.cc. Do not use a class simply to group static functions, unless they are function templates which need to be partially specialised. Otherwise, static methods of a class should generally be closely related to instances of the class or the class’s static data.
- Pros:
Nonmember and static member functions can be useful in some situations. Putting nonmember functions in a namespace avoids polluting the global namespace.
- Cons:
Nonmember and static member functions may make more sense as members of a new class, especially if they access external resources or have significant dependencies.
- Decision:
Sometimes it is useful to define a function not bound to a class instance. Such a function can be either a static member or a nonmember function. Nonmember functions should not depend on external variables, and should nearly always exist in a namespace. Do not create classes only to group static member functions, unless they are function templates which need to be partially specialised; otherwise, this is no different than just giving the function names a common prefix, and such grouping is usually unnecessary anyway.
If you define a nonmember function and it is only needed in its .cc file, use internal linkage to limit its scope.
Local Variables¶
Place a function’s variables in the narrowest scope possible, and initialise variables in the declaration.
C++ allows you to declare variables anywhere in a function. We encourage you to declare them in as local a scope as possible, and as close to the first use as possible. This makes it easier for the reader to find the declaration and see what type the variable is and what it was initialised to. In particular, initialisation should be used instead of declaration and assignment, e.g.:
int i;
i = f(); // Bad -- initialisation separate from declaration.
int j{g()}; // Good -- declaration has initialisation.
std::vector<int> v;
v.push_back(1); // Prefer initialising using brace initialisation.
v.push_back(2);
std::vector<int> v = {1, 2}; // Good -- v starts initialised.
Prefer C++11-style universal initialisation (int i{0}) over legacy initialisation (int i = 0).
Variables needed for if, while and for statements should normally be declared within those statements, so that such variables are confined to those scopes. E.g.:
for (size_t i{0}; i < DimS; ++i) {
...
}
There is one caveat: if the variable is an object, its constructor is invoked every time it enters scope and is created, and its destructor is invoked every time it goes out of scope.
// Inefficient implementation:
for (int i = 0; i < 1000000; ++i) {
Foo f; // My ctor and dtor get called 1000000 times each.
f.do_something(i);
}
It may be more efficient to declare such a variable used in a loop outside that loop:
Foo f; // My ctor and dtor get called once each.
for (int i = 0; i < 1000000; ++i) {
f.do_something(i);
}
Static and Global Variables¶
Objects with static storage duration are forbidden unless they are trivially destructible. Informally this means that the destructor does not do anything, even taking member and base destructors into account. More formally it means that the type has no user-defined or virtual destructor and that all bases and non-static members are trivially destructible. Static function-local variables may use dynamic initialisation. Use of dynamic initialisation for static class member variables or variables at namespace scope is discouraged, but allowed in limited circumstances; see below for details.
As a rule of thumb: a global variable satisfies these requirements if its declaration, considered in isolation, could be constexpr.
- Definition:
Every object has a storage duration, which correlates with its lifetime. Objects with static storage duration live from the point of their initialisation until the end of the program. Such objects appear as variables at namespace scope (“global variables”), as static data members of classes, or as function-local variables that are declared with the
staticspecifier. Function-local static variables are initialised when control first passes through their declaration; all other objects with static storage duration are initialised as part of program start-up. All objects with static storage duration are destroyed at program exit (which happens before unjoined threads are terminated).
Initialisation may be dynamic, which means that something non-trivial happens during initialisation. (For example, consider a constructor that allocates memory, or a variable that is initialised with the current process ID.) The other kind of initialisation is static initialisation. The two aren’t quite opposites, though: static initialisation always happens to objects with static storage duration (initialising the object either to a given constant or to a representation consisting of all bytes set to zero), whereas dynamic initialisation happens after that, if required.
- Pros:
Global and static variables are very useful for a large number of applications: named constants, auxiliary data structures internal to some translation unit, command-line flags, logging, registration mechanisms, background infrastructure, etc.
- Cons:
Global and static variables that use dynamic initialisation or have non-trivial destructors create complexity that can easily lead to hard-to-find bugs. Dynamic initialisation is not ordered across translation units, and neither is destruction (except that destruction happens in reverse order of initialisation). When one initialisation refers to another variable with static storage duration, it is possible that this causes an object to be accessed before its lifetime has begun (or after its lifetime has ended). Moreover, when a program starts threads that are not joined at exit, those threads may attempt to access objects after their lifetime has ended if their destructor has already run.
- Decision:
Decision on destruction
When destructors are trivial, their execution is not subject to ordering at all (they are effectively not “run”); otherwise we are exposed to the risk of accessing objects after the end of their lifetime. Therefore, we only allow objects with static storage duration if they are trivially destructible. Fundamental types (like pointers and int) are trivially destructible, as are arrays of trivially destructible types. Note that variables marked with
constexprare trivially destructible.const int kNum{10}; // allowed struct X { int n; }; const X kX[]{{1}, {2}, {3}}; // allowed void foo() { static const char* const kMessages[]{"hello", "world"}; // allowed } // allowed: constexpr guarantees trivial destructor constexpr std::array<int, 3> kArray {{1, 2, 3}};
// bad: non-trivial destructor const string kFoo("foo"); // bad for the same reason, even though kBar is a reference (the // rule also applies to lifetime-extended temporary objects) const string& kBar(StrCat("a", "b", "c")); void bar() { // bad: non-trivial destructor static std::map<int, int> kData{{1, 0}, {2, 0}, {3, 0}}; }
Note that references are not objects, and thus they are not subject to the constraints on destructibility. The constraint on dynamic initialisation still applies, though. In particular, a function-local static reference of the form
static T& t = *new T; is allowed.Decision on initialisation
Initialisation is a more complex topic. This is because we must not only consider whether class constructors execute, but we must also consider the evaluation of the initialiser:
int n{5}; // fine int m{f()}; // ? (depends on f) Foo x; // ? (depends on Foo::Foo) Bar y{g()}; // ? (depends on g and on Bar::Bar)
All but the first statement expose us to indeterminate initialisation ordering.
The concept we are looking for is called constant initialisation in the formal language of the C++ standard. It means that the initialising expression is a constant expression, and if the object is initialised by a constructor call, then the constructor must be specified as
constexpr, too:struct Foo { constexpr Foo(int) {} }; int n{5}; // fine, 5 is a constant expression Foo x(2); // fine, 2 is a constant expression and the chosen constructor is constexpr Foo a[] { Foo(1), Foo(2), Foo(3) }; // fine
Constant initialisation is always allowed. Constant initialisation of static storage duration variables should be marked with
constexpr. Any non-local static storage duration variable that is not so marked should be presumed to have dynamic initialisation, and reviewed very carefully.By contrast, the following initialisations are problematic:
time_t time(time_t*); // not ``constexpr``! int f(); // not ``constexpr``! struct Bar { Bar() {} }; time_t m{time(nullptr)}; // initialising expression not a constant expression Foo y(f()); // ditto Bar b; // chosen constructor Bar::Bar() not ``constexpr``
Dynamic initialisation of nonlocal variables is discouraged, and in general it is forbidden. However, we do permit it if no aspect of the program depends on the sequencing of this initialisation with respect to all other initialisations. Under those restrictions, the ordering of the initialisation does not make an observable difference. For example:
int p{getpid()}; // allowed, as long as no other static variable // uses p in its own initialisation
Dynamic initialisation of static local variables is allowed (and common).
Common patterns
Global strings: if you require a global or static string constant, consider using a simple character array, or a char pointer to the first element of a string literal. String literals have static storage duration already and are usually sufficient.
Maps, sets, and other dynamic containers: if you require a static, fixed collection, such as a set to search against or a lookup table, you cannot use the dynamic containers from the standard library as a static variable, since they have non-trivial destructors. Instead, consider a simple array of trivial types, e.g. an array of arrays of
int(for a “map frominttoint”), or an array of pairs (e.g. pairs ofintandconst char*). For small collections, linear search is entirely sufficient (and efficient, due to memory locality). If necessary, keep the collection in sorted order and use a binary search algorithm. If you do really prefer a dynamic container from the standard library, consider using a function-local static pointer, as described below.Smart pointers (
std::unique_ptr,std::shared_ptr): smart pointers execute cleanup during destruction and are therefore forbidden. Consider whether your use case fits into one of the other patterns described in this section. One simple solution is to use a plain pointer to a dynamically allocated object and never delete it (see last item).Static variables of custom types: if you require
static, constant data of a type that you need to define yourself, give the type a trivial destructor and aconstexprconstructor.If all else fails, you can create an object dynamically and never delete it by binding the pointer to a function-local static pointer variable:
static const auto* const impl = new T(args...); (If the initialisation is more complex, it can be moved into a function or lambda expression.)
thread_local Variables¶
thread_local variables that aren’t declared inside a function must be initialised with a true compile-time constant. Prefer thread_local over other ways of defining thread-local data.
- Definition:
Starting with C++11, variables can be declared with the
thread_localspecifier:thread_local Foo foo{...};
Such a variable is actually a collection of objects, so that when different threads access it, they are actually accessing different objects.
thread_localvariables are much like static storage duration variables in many respects. For instance, they can be declared at namespace scope, inside functions, or as static class members, but not as ordinary class members.thread_localvariable instances are initialised much like static variables, except that they must be initialised separately for each thread, rather than once at program startup. This means thatthread_localvariables declared within a function are safe, but otherthread_localvariables are subject to the same initialisation-order issues as static variables (and more besides).thread_localvariable instances are destroyed when their thread terminates, so they do not have the destruction-order issues of static variables.
Pros:
Thread-local data is inherently safe from races (because only one thread can ordinarily access it), which makes
thread_localuseful for concurrent programming.
thread_localis the only standard-supported way of creating thread-local data.
- Cons:
Accessing a
thread_localvariable may trigger execution of an unpredictable and uncontrollable amount of other code.thread_localvariables are effectively global variables, and have all the drawbacks of global variables other than lack of thread-safety.The memory consumed by a
thread_localvariable scales with the number of running threads (in the worst case), which can be quite large in a program.An ordinary class member cannot be
thread_local.thread_localmay not be as efficient as certain compiler intrinsics.
- Decision:
thread_localvariables inside a function have no safety concerns, so they can be used without restriction. Note that you can use a function-scopethread_localto simulate a class- or namespace-scopethread_localby defining a function or static method that exposes it:Foo& MyThreadLocalFoo() { thread_local Foo result{ComplicatedInitialisation()}; return result; }
thread_localvariables at class or namespace scope must be initialised with a true compile-time constant (i.e. they must have no dynamic initialisation). To enforce this,thread_localvariables at class or namespace scope must be annotated withconstexpr:constexpr thread_local Foo foo = ...;
thread_localshould be preferred over other mechanisms for defining thread-local data.
Classes¶
Classes are the fundamental unit of code in C++. Naturally, we use them extensively. This section lists the main dos and don’ts you should follow when writing a class.
Doing Work in Constructors¶
Avoid virtual method calls in constructors, and avoid initialisation that can fail if you can’t signal an error.
- Definition:
It is possible to perform arbitrary initialisation in the body of the constructor.
- Pros:
No need to worry about whether the class has been initialised or not.
Objects that are fully initialised by constructor call can be const and may also be easier to use with standard containers or algorithms.
- Cons:
If the work calls virtual functions, these calls will not get dispatched to the subclass implementations. Future modification to your class can quietly introduce this problem even if your class is not currently subclassed, causing much confusion.
There is no easy way for constructors to signal errors, short of crashing the program (not always appropriate) or using exceptions.
If the work fails, we now have an object whose initialisation code failed, so it may be an unusual state requiring a
bool is_valid()state checking mechanism (or similar) which is easy to forget to call.You cannot take the address of a constructor, so whatever work is done in the constructor cannot easily be handed off to, for example, another thread.
- Decision:
Constructors should never call virtual functions. If appropriate for your code , terminating the program may be an appropriate error handling response. Otherwise, consider a factory function or
initialise()method as described in TotW #42 . Avoidinitialise()methods on objects with no other states that affect which public methods may be called (semi-constructed objects of this form are particularly hard to work with correctly).
Implicit Conversions¶
Do not define implicit conversions. Use the explicit keyword for conversion operators and single-argument constructors.
- Definition:
Implicit conversions allow an object of one type (called the source type) to be used where a different type (called the destination type) is expected, such as when passing an
intargument to a function that takes adoubleparameter.In addition to the implicit conversions defined by the language, users can define their own, by adding appropriate members to the class definition of the source or destination type. An implicit conversion in the source type is defined by a type conversion operator named after the destination type (e.g.
operator bool()). An implicit conversion in the destination type is defined by a constructor that can take the source type as its only argument (or only argument with no default value).The
explicitkeyword can be applied to a constructor or (since C++11) a conversion operator, to ensure that it can only be used when the destination type is explicit at the point of use, e.g. with a cast. This applies not only to implicit conversions, but to C++11’s list initialisation syntax:class Foo { explicit Foo(int x, double y); ... }; void Func(Foo f); Func({42, 3.14}); // Error
This kind of code isn’t technically an implicit conversion, but the language treats it as one as far as
explicitis concerned.- Pros:
Implicit conversions can make a type more usable and expressive by eliminating the need to explicitly name a type when it’s obvious.
Implicit conversions can be a simpler alternative to overloading, such as when a single function with a
string_viewparameter takes the place of separate overloads forstringandconst char*.List initialisation syntax is a concise and expressive way of initialising objects.
- Cons:
Implicit conversions can hide type-mismatch bugs, where the destination type does not match the user’s expectation, or the user is unaware that any conversion will take place.
Implicit conversions can make code harder to read, particularly in the presence of overloading, by making it less obvious what code is actually getting called.
Constructors that take a single argument may accidentally be usable as implicit type conversions, even if they are not intended to do so.
When a single-argument constructor is not marked
explicit, there’s no reliable way to tell whether it’s intended to define an implicit conversion, or the author simply forgot to mark it.It’s not always clear which type should provide the conversion, and if they both do, the code becomes ambiguous.
List initialisation can suffer from the same problems if the destination type is implicit, particularly if the list has only a single element.
- Decision:
Type conversion operators, and constructors that are callable with a single argument, must be marked
explicitin the class definition. As an exception, copy and move constructors should not beexplicit, since they do not perform type conversion. Implicit conversions can sometimes be necessary and appropriate for types that are designed to transparently wrap other types. In that case, raise an issue.Constructors that cannot be called with a single argument may omit
explicit. Constructors that take a singlestd::initialiser_listparameter should also omitexplicit, in order to support copy-initialisation (e.g.MyType m{1, 2};).
Copyable and Movable Types¶
A class’s public API should make explicit whether the class is copyable, move-only, or neither copyable nor movable. Support copying and/or moving if these operations are clear and meaningful for your type.
- Definition:
A movable type is one that can be initialised and assigned from temporaries.
A copyable type is one that can be initialised or assigned from any other object of the same type (so is also movable by definition), with the stipulation that the value of the source does not change.
std::unique_ptr<int>is an example of a movable but not copyable type (since the value of the sourcestd::unique_ptr<int>must be modified during assignment to the destination).intandstringare examples of movable types that are also copyable. (Forint, the move and copy operations are the same; forstring, there exists a move operation that is less expensive than a copy.)
For user-defined types, the copy behaviour is defined by the copy constructor and the copy-assignment operator. Move behaviour is defined by the move constructor and the move-assignment operator, if they exist, or by the copy constructor and the copy-assignment operator otherwise.
The copy/move constructors can be implicitly invoked by the compiler in some situations, e.g. when passing objects by value.
- Pros:
Objects of copyable and movable types can be passed and returned by value, which makes APIs simpler, safer, and more general. Unlike when passing objects by pointer or reference, there’s no risk of confusion over ownership, lifetime, mutability, and similar issues, and no need to specify them in the contract. It also prevents non-local interactions between the client and the implementation, which makes them easier to understand, maintain, and optimise by the compiler. Further, such objects can be used with generic APIs that require pass-by-value, such as most containers, and they allow for additional flexibility in e.g., type composition.
Copy/move constructors and assignment operators are usually easier to define correctly than alternatives like
clone(),copy_from()orswap(), because they can be generated by the compiler, either implicitly or with= default. They are concise, and ensure that all data members are copied. Copy and move constructors are also generally more efficient, because they don’t require heap allocation or separate initialisation and assignment steps, and they’re eligible for optimisations such as copy elision.Move operations allow the implicit and efficient transfer of resources out of rvalue objects. This allows a plainer coding style in some cases.
- Cons:
Some types do not need to be copyable, and providing copy operations for such types can be confusing, nonsensical, or outright incorrect. Types representing singleton objects (Registerer), objects tied to a specific scope (Cleanup), or closely coupled to object identity (Mutex) cannot be copied meaningfully. Copy operations for base class types that are to be used polymorphically are hazardous, because use of them can lead to object slicing. Defaulted or carelessly-implemented copy operations can be incorrect, and the resulting bugs can be confusing and difficult to diagnose.
Copy constructors are invoked implicitly, which makes the invocation easy to miss. This may cause confusion for programmers used to languages where pass-by-reference is conventional or mandatory. It may also encourage excessive copying, which can cause performance problems.
- Decision:
Every class’s public interface should make explicit which copy and move operations the class supports. This should usually take the form of explicitly declaring and/or deleting the appropriate operations in the public section of the declaration.
Specifically, a copyable class should explicitly declare the copy operations, a move-only class should explicitly declare the move operations, and a non-copyable/movable class should explicitly delete the copy operations. Explicitly declaring or deleting all four copy/move operations is required. If you provide a copy or move assignment operator, you must also provide the corresponding constructor.
class Copyable { public: //! Default constructor Copyable() = delete; //! Copy constructor Copyable(const Copyable &other); //! Move constructor Copyable(Copyable &&other) = delete; //! Destructor virtual ~Copyable() noexcept; //! Copy assignment operator Copyable& operator=(const Copyable &other); //! Move assignment operator Copyable& operator=(Copyable &&other) = delete; protected: ... private: ... }; class MoveOnly { public: //! Default constructor MoveOnly() = delete; //! Copy constructor MoveOnly(const MoveOnly &other) = delete; //! Move constructor MoveOnly(MoveOnly &&other); //! Destructor virtual ~MoveOnly() noexcept; //! Copy assignment operator MoveOnly& operator=(const MoveOnly &other) = delete; //! Move assignment operator MoveOnly& operator=(MoveOnly &&other); protected: ... private: ... }; class NotCopyableNorMovable { public: //! Default constructor NotCopyableNorMovable() = delete; //! Copy constructor NotCopyableNorMovable(const NotCopyableNorMovable &other) = delete; //! Move constructor NotCopyableNorMovable(NotCopyableNorMovable &&other); //! Destructor virtual ~NotCopyableNorMovable() noexcept; //! Copy assignment operator NotCopyableNorMovable& operator=(const NotCopyableNorMovable &other) = delete; //! Move assignment operator NotCopyableNorMovable& operator=(NotCopyableNorMovable &&other) = delete; protected: ... private: ... };
These declarations/deletions can be omitted only if they are obvious: for example, if a base class isn’t copyable or movable, derived classes naturally won’t be either. Similarly, a
struct’s copyability/movability is normally determined by the copyability/movability of its data members. Note that if you explicitly declare or delete any of the copy/move operations, the others are not obvious, and so this paragraph does not apply (in particular, the rules in this section that apply toclasses also apply tostructs that declare or delete any copy/move operations).A type should not be copyable/movable if it incurs unexpected costs. Move operations for copyable types are strictly a performance optimisation and are a potential source of bugs and complexity, so define them if they have a chance of being more efficient than the corresponding copy operations. If your type provides copy operations, it is recommended that you design your class so that the default implementation of those operations is correct. Remember to review the correctness of any defaulted operations as you would any other code.
Structs vs. Classes¶
Use a struct only for passive objects that carry data or collections of templated static member functions that need to be partially specialised; everything else is a class.
The struct and class keywords behave almost identically in C++. We add our own semantic meanings to each keyword, so you should use the appropriate keyword for the data-type you’re defining.
structs should be used for passive objects that carry data, and may have associated constants, but lack any functionality other than access/setting the data members. The accessing/setting of fields is done by directly accessing the fields rather than through method invocations.
Methods should only be used in templated static method-only structs. See, e.g.:
//! static inline implementation of Hooke's law
template <Dim_t Dim, class Strain_t, class Tangent_t>
struct Hooke {
/**
* compute Lamé's first constant
* @param young: Young's modulus
* @param poisson: Poisson's ratio
*/
inline static constexpr Real
compute_lambda(const Real & young, const Real & poisson) {
return convert_elastic_modulus<ElasticModulus::lambda,
ElasticModulus::Young,
ElasticModulus::Poisson>(young, poisson);
}
/**
* compute Lamé's second constant (i.e., shear modulus)
* @param young: Young's modulus
* @param poisson: Poisson's ratio
*/
inline static constexpr Real
compute_mu(const Real & young, const Real & poisson) {
return convert_elastic_modulus<ElasticModulus::Shear,
ElasticModulus::Young,
ElasticModulus::Poisson>(young, poisson);
}
/**
* compute the bulk modulus
* @param young: Young's modulus
* @param poisson: Poisson's ratio
*/
inline static constexpr Real
compute_K(const Real & young, const Real & poisson) {
return convert_elastic_modulus<ElasticModulus::Bulk,
ElasticModulus::Young,
ElasticModulus::Poisson>(young, poisson);
}
/**
* compute the stiffness tensor
* @param lambda: Lamé's first constant
* @param mu: Lamé's second constant (i.e., shear modulus)
*/
inline static Eigen::TensorFixedSize<Real, Eigen::Sizes<Dim, Dim, Dim, Dim>>
compute_C(const Real & lambda, const Real & mu) {
return lambda*Tensors::outer<Dim>(Tensors::I2<Dim>(),Tensors::I2<Dim>()) +
2*mu*Tensors::I4S<Dim>();
}
/**
* compute the stiffness tensor
* @param lambda: Lamé's first constant
* @param mu: Lamé's second constant (i.e., shear modulus)
*/
inline static T4Mat<Real, Dim>
compute_C_T4(const Real & lambda, const Real & mu) {
return lambda*Matrices::Itrac<Dim>() + 2*mu*Matrices::Isymm<Dim>();
}
/**
* return stress
* @param lambda: First Lamé's constant
* @param mu: Second Lamé's constant (i.e. shear modulus)
* @param E: Green-Lagrange or small strain tensor
*/
template <class s_t>
inline static decltype(auto)
evaluate_stress(const Real & lambda, const Real & mu, s_t && E) {
return E.trace()*lambda * Strain_t::Identity() + 2*mu*E;
}
/**
* return stress and tangent stiffness
* @param lambda: First Lamé's constant
* @param mu: Second Lamé's constant (i.e. shear modulus)
* @param E: Green-Lagrange or small strain tensor
* @param C: stiffness tensor (Piola-Kirchhoff 2 (or σ) w.r.t to `E`)
*/
template <class s_t>
inline static decltype(auto)
evaluate_stress(const Real & lambda, const Real & mu,
Tangent_t && C, s_t && E) {
return std::make_tuple
(std::move(evaluate_stress(lambda, mu, std::move(E))),
std::move(C));
}
};
The goal of such static member functions-only structs is to instantiate a set of function templates with consistent template parameters without repeating those parameters.
If more functionality is required, a class is more appropriate. If in doubt, make it a class.
For consistency with STL, you can use struct instead of class for functors and traits.
Inheritance¶
Composition is often more appropriate than inheritance. When using inheritance, make it public.
- Definition:
When a sub-class inherits from a base class, it includes the definitions of all the data and operations that the parent base class defines. In practice, inheritance is used in two major ways in C++: implementation inheritance, in which actual code is inherited by the child, and interface inheritance, in which only method names are inherited.
- Pros:
Implementation inheritance reduces code size by re-using the base class code as it specializes an existing type. Because inheritance is a compile-time declaration, you and the compiler can understand the operation and detect errors. Interface inheritance can be used to programmatically enforce that a class expose a particular API. Again, the compiler can detect errors, in this case, when a class does not define a necessary method of the API.
- Cons:
For implementation inheritance, because the code implementing a sub-class is spread between the base and the sub-class, it can be more difficult to understand an implementation. The sub-class cannot override functions that are not virtual, so the sub-class cannot change implementation.
- Decision:
All inheritance should be
public. If you want to do private inheritance, you should be including an instance of the base class as a member instead.Do not overuse implementation inheritance. Composition is often more appropriate. Try to restrict use of inheritance to the “is-a” case:
BarsubclassesFooif it can reasonably be said thatBar“is a kind of”Foo.Limit the use of protected to those member functions that might need to be accessed from subclasses. Note that data members should be private.
Explicitly annotate overrides of virtual functions or virtual destructors with exactly one of either the
overrideor (less frequently)override finalspecifier. Do not usevirtualwhen declaring anoverride. Rationale: A function or destructor markedoverrideorfinalthat is not anoverrideof a base class virtual function will not compile, and this helps catch common errors. The specifiers serve as documentation; if no specifier is present, the reader has to check all ancestors of the class in question to determine if the function or destructor isvirtualor not.
Multiple Inheritance¶
Only very rarely is multiple implementation inheritance actually useful. We allow multiple inheritance only when at most one of the base classes has an implementation; all other base classes must be pure interface classes.
- Definition:
Multiple inheritance allows a sub-class to have more than one base class. We distinguish between base classes that are pure interfaces and those that have an implementation.
- Pros:
Multiple implementation inheritance may let you re-use even more code than single inheritance (see Inheritance).
- Cons:
Only very rarely is multiple implementation inheritance actually useful. When multiple implementation inheritance seems like the solution, you can usually find a different, more explicit, and cleaner solution.
- Decision:
Multiple inheritance is allowed only when all superclasses, with the possible exception of the first one, are pure interfaces.
- Note:
There is an exception to this rule on Windows.
Interfaces¶
- Definition:
A class is a pure interface if it meets the following requirements:
It has only public pure virtual (
= 0) methods and static methods (but see below for destructor).It may not have non-static data members.
It need not have any constructors defined. If a constructor is provided, it must take no arguments and it must be protected.
If it is a subclass, it may only be derived from classes that satisfy these conditions.
An interface class can never be directly instantiated because of the pure virtual method(s) it declares. To make sure all implementations of the interface can be destroyed correctly, the interface must also declare a virtual destructor (in an exception to the first rule, this should not be pure). See Stroustrup, The C++ Programming Language, 4th edition, 2014, section 20.3 for details.
Operator Overloading¶
Overload operators judiciously.
- Definition:
C++ permits user code to declare overloaded versions of the built-in operators using the
operatorkeyword, so long as one of the parameters is a user-defined type. Theoperatorkeyword also permits user code to define new kinds of literals usingoperator"", and to define type-conversion functions such asoperator bool().- Pros:
Operator overloading can make code more concise and intuitive by enabling user-defined types to behave the same as built-in types. Overloaded operators are the idiomatic names for certain operations (e.g.
==,<,=, and<<), and adhering to those conventions can make user-defined types more readable and enable them to interoperate with libraries that expect those names.User-defined literals are a very concise notation for creating objects of user-defined types.
- Cons:
Providing a correct, consistent, and unsurprising set of operator overloads requires some care, and failure to do so can lead to confusion and bugs.
Overuse of operators can lead to obfuscated code, particularly if the overloaded operator’s semantics don’t follow convention.
The hazards of function overloading apply just as much to operator overloading, if not more so.
Operator overloads can fool our intuition into thinking that expensive operations are cheap, built-in operations.
Finding the call sites for overloaded operators may require a search tool that’s aware of C++ syntax, rather than e.g. grep.
If you get the argument type of an overloaded operator wrong, you may get a different overload rather than a compiler error. For example,
foo < barmay do one thing, while&foo < &bardoes something totally different.Certain operator overloads are inherently hazardous. Overloading unary
&can cause the same code to have different meanings depending on whether the overload declaration is visible. Overloads of&&,||, and,(comma) cannot match the evaluation-order semantics of the built-in operators.Operators are often defined outside the class, so there’s a risk of different files introducing different definitions of the same operator. If both definitions are linked into the same binary, this results in undefined behavior, which can manifest as subtle run-time bugs.
User-defined literals allow the creation of new syntactic forms that are unfamiliar even to experienced C++ programmers.
- Decisions:
Define overloaded operators only if their meaning is obvious, unsurprising, and consistent with the corresponding built-in operators. For example, use
|as a bitwise- or logical-or, not as a shell-style pipe.Define operators only on your own types. More precisely, define them in the same headers,
.ccfiles, and namespaces as the types they operate on. That way, the operators are available wherever the type is, minimising the risk of multiple definitions. If possible, avoid defining operators as templates, because they must satisfy this rule for any possible template arguments. If you define an operator, also define any related operators that make sense, and make sure they are defined consistently. For example, if you overload<, overload all the comparison operators, and make sure<and>never return true for the same arguments.Prefer to define non-modifying binary operators as non-member functions. If a binary operator is defined as a class member, implicit conversions will apply to the right-hand argument, but not the left-hand one. It will confuse your users if
a < bcompiles butb < adoesn’t.Don’t go out of your way to avoid defining operator overloads. For example, prefer to define
==,=, and<<, rather thanequals(),copy_from(), andprint_to(). Conversely, don’t define operator overloads just because other libraries expect them. For example, if your type doesn’t have a natural ordering, but you want to store it in astd::set, use a custom comparator rather than overloading<.
Do not overload &&, ||, , (comma), or unary &.
Type conversion operators are covered in Implicit Conversions. The = operator is covered in Copyable and Movable Types. Overloading << for use with streams is covered in Streams. See also the rules on function overloading, which apply to operator overloading as well.
Access Control¶
Make data members protected, unless they are static const (and follow the naming convention for constants).
Declaration Order¶
Group similar declarations together, placing public parts earlier.
A class definition should usually start with a public: section, followed by protected:, then private:. Omit sections that would be empty.
Within each section, generally prefer grouping similar kinds of declarations together, and generally prefer the following order: types (including using, and nested structs and classes), constants, factory functions, constructors, assignment operators, destructor, all other methods, data members.
Do not put large method definitions inline in the class definition. Trivial, performance-critical, or template methods may be defined inline. See Inline Functions for more details.
Functions¶
Output Parameters¶
Prefer using return values rather than output parameters. If output-only parameters are used they should appear after input parameters.
The output(s) of a C++ function is/are naturally provided via a (tuple of) return value and sometimes via output parameters.
Prefer using return values and return value tuples over output parameters since they improve readability and oftentimes provide the same or better performance.
Parameters are either input to the function, output from the function, or both. Input parameters are usually values or const references, while output and input/output parameters will be references to non-const.
When ordering function parameters, put all input-only parameters before any output parameters. In particular, do not add new parameters to the end of the function just because they are new; place new input-only parameters before the output parameters.
This is not a hard-and-fast rule. Parameters that are both input and output (often classes/structs) muddy the waters, and, as always, consistency with related functions may require you to bend the rule.
Write Short Functions¶
Prefer small and focused functions.
We recognise that long functions are sometimes appropriate, so no hard limit is placed on functions length. If a function exceeds about 40 lines, think about whether it can be broken up without harming the structure of the program.
Even if your long function works perfectly now, someone modifying it in a few months may add new behaviour. This could result in bugs that are hard to find. Keeping your functions short and simple makes it easier for other people to read and modify your code.
You could find long and complicated functions when working with some code. Do not be intimidated by modifying existing code: if working with such a function proves to be difficult, you find that errors are hard to debug, or you want to use a piece of it in several different contexts, consider breaking up the function into smaller and more manageable pieces.
Reference Arguments¶
All input parameters passed by reference must be labelled const, Output and input/output parameters can be passed as references, smart pointers, or std::optional. There are no raw pointers within µSpectre, ever.
- Definition:
In C, if a function needs to modify a variable, the parameter must use a pointer, e.g.,
int foo(int *pval). In C++, the function can alternatively declare a reference parameter:int foo(int &val).- Pros:
Defining a parameter as reference avoids ugly code like
(*pval)++. Necessary for some applications like copy constructors. Makes it clear, unlike with pointers, that a null pointer is not a possible value.- Cons:
References can be confusing to absolute beginners, as they have value syntax but pointer semantics.
- Decision:
The one hard rule in µSpectre is that no raw pointers will be tolerated (with the obvious exception of interacting with third-party APIs). Pointers are to be considered a bug-generating relic of a darker time when
gotostatements were allowed to exist. If you need to mimic the questionable practice of passing a pointer that could benullptrto indicate that there is no value, usestd::optional.
Function Overloading¶
Use overloaded functions (including constructors) only if a reader looking at a call site can get a good idea of what is happening without having to first figure out exactly which overload is being called.
- Definition:
You may write a function that takes a
const string&and overload it with another that takesconst char*. However, in this case considerstd::string_viewinstead.class MyClass { public: void Analyze(const string &text); void Analyze(const char *text, size_t textlen); };
- Pros:
Overloading can make code more intuitive by allowing an identically-named function to take different arguments. It may be necessary for templated code, and it can be convenient for Visitors.
- Cons:
If a function is overloaded by the argument types alone, a reader may have to understand C++’s complex matching rules in order to tell what’s going on. Also many people are confused by the semantics of inheritance if a derived class overrides only some of the variants of a function.
- Decision:
You may overload a function when there are no semantic differences between variants, or when the differences are clear at the call site.
If you are overloading a function to support variable number of arguments of the same type, consider making it take a STL container so that the user can use an initialiser list to specify the arguments.
Default Arguments¶
Default arguments are allowed on non-virtual functions when the default is guaranteed to always have the same value. Follow the same restrictions as for function overloading, and prefer overloaded functions if the readability gained with default arguments doesn’t outweigh the downsides below.
- Pros:
Often you have a function that uses default values, but occasionally you want to override the defaults. Default parameters allow an easy way to do this without having to define many functions for the rare exceptions. Compared to overloading the function, default arguments have a cleaner syntax, with less boilerplate and a clearer distinction between ‘required’ and ‘optional’ arguments.
- Cons:
Defaulted arguments are another way to achieve the semantics of overloaded functions, so all the reasons not to overload functions apply.
The defaults for arguments in a virtual function call are determined by the static type of the target object, and there’s no guarantee that all overrides of a given function declare the same defaults.
Default parameters are re-evaluated at each call site, which can bloat the generated code. Readers may also expect the default’s value to be fixed at the declaration instead of varying at each call.
Function pointers are confusing in the presence of default arguments, since the function signature often doesn’t match the call signature. Adding function overloads avoids these problems.
- Decision:
Default arguments are banned on virtual functions, where they don’t work properly, and in cases where the specified default might not evaluate to the same value depending on when it was evaluated. (For example, don’t write
void f(int n = counter++);.)In some other cases, default arguments can improve the readability of their function declarations enough to overcome the downsides above, so they are allowed.
Trailing Return Type Syntax¶
Use trailing return types only where using the ordinary syntax (leading return types) is impractical or much less readable.
- Definition:
C++ allows two different forms of function declarations. In the older form, the return type appears before the function name. For example:
int foo(int x);
The new form, introduced in C++11, uses the auto keyword before the function name and a trailing return type after the argument list. For example, the declaration above could equivalently be written:
auto foo(int x) -> int;
The trailing return type is in the function’s scope. This doesn’t make a difference for a simple case like int but it matters for more complicated cases, like types declared in class scope or types written in terms of the function parameters.
- Pros:
Trailing return types are the only way to explicitly specify the return type of a lambda expression. In some cases the compiler is able to deduce a lambda’s return type, but not in all cases. Even when the compiler can deduce it automatically, sometimes specifying it explicitly would be clearer for readers.
Sometimes it’s easier and more readable to specify a return type after the function’s parameter list has already appeared. This is particularly true when the return type depends on template parameters. For example:
template <typename T, typename U> auto add(T t, U u) -> decltype(t + u);
versus
template <typename T, typename U> decltype(declval<T&>() + declval<U&>()) add(T t, U u);
- Decision:
In most cases, continue to use the older style of function declaration where the return type goes before the function name. Use the new trailing-return-type form only in cases where it’s required (such as lambdas) or where, by putting the type after the function’s parameter list, it allows you to write the type in a much more readable way.
Ownership and linting¶
There are various tricks and utilities that we use to make C++ code more robust, and various ways we use C++ that may differ from what you see elsewhere.
Ownership and Smart Pointers¶
Prefer to have single, fixed owners for dynamically allocated objects. Prefer to transfer ownership with smart pointers.
- Definition:
“Ownership” is a bookkeeping technique for managing dynamically allocated memory (and other resources). The owner of a dynamically allocated object is an object or function that is responsible for ensuring that it is deleted when no longer needed. Ownership can sometimes be shared, in which case the last owner is typically responsible for deleting it. Even when ownership is not shared, it can be transferred from one piece of code to another.
“Smart” pointers are classes that act like pointers, e.g. by overloading the
*and->operators. Some smart pointer types can be used to automate ownership bookkeeping, to ensure these responsibilities are met.std::unique_ptris a smart pointer type introduced in C++11, which expresses exclusive ownership of a dynamically allocated object; the object is deleted when thestd::unique_ptrgoes out of scope. It cannot be copied, but can be moved to represent ownership transfer.std::shared_ptris a smart pointer type that expresses shared ownership of a dynamically allocated object.std::shared_ptrscan be copied; ownership of the object is shared among all copies, and the object is deleted when the laststd::shared_ptris destroyed.
Pros:
It’s virtually impossible to manage dynamically allocated memory without some sort of ownership logic.
Transferring ownership of an object can be cheaper than copying it (if copying it is even possible).
Transferring ownership can be simpler than ‘borrowing’ a pointer or reference, because it reduces the need to coordinate the lifetime of the object between the two users.
Smart pointers can improve readability by making ownership logic explicit, self-documenting, and unambiguous.
Smart pointers can eliminate manual ownership bookkeeping, simplifying the code and ruling out large classes of errors.
For const objects, shared ownership can be a simple and efficient alternative to deep copying.
- Cons:
Ownership must be represented and transferred via smart pointers. Pointer semantics are more complicated than value semantics, especially in APIs: you have to worry not just about ownership, but also aliasing, lifetime, and mutability, among other issues.
The performance costs of value semantics are often overestimated, so the performance benefits of ownership transfer might not justify the readability and complexity costs.
APIs that transfer ownership force their clients into a single memory management model.
Code using smart pointers is less explicit about where the resource releases take place.
Shared ownership can be a tempting alternative to careful ownership design, obfuscating the design of a system.
Shared ownership requires explicit bookkeeping at run-time, which can be costly.
In some cases (e.g. cyclic references), objects with shared ownership may never be deleted.
- Decision:
If dynamic allocation is necessary, prefer to keep ownership with the code that allocated it. If other code needs momentary access to the object (i.e., there is no risk of the other code accessing it later, after the object may have been destroyed), consider passing it a reference without transferring ownership. Prefer to use
std::unique_ptrto make ownership transfer explicit. For example:std::unique_ptr<Foo> FooFactory(); void FooConsumer(std::unique_ptr<Foo> ptr);
Do not design your code to use shared ownership without a very good reason. One such reason is to avoid expensive copy operations. If you do use shared ownership, prefer to use
std::shared_ptr.Never use
std::auto_ptrit has no longer any value. Instead, usestd::unique_ptr.
cpplint¶
Use cpplint.py to detect style errors.
cpplint.py is a tool that reads a source file and identifies many style errors. It is not perfect, and has both false positives and false negatives, but it is still a valuable tool. False positives can be ignored by putting // NOLINT at the end of the line or // NOLINTNEXTLINE in the previous line.
Other C++ Features¶
Rvalue References¶
Use rvalue references to define move constructors and move assignment operators, or for perfect forwarding.
- Definition:
Rvalue references are a type of reference that can only bind to temporary objects. The syntax is similar to traditional reference syntax. For example,
void f(string&& s);declares a function whose argument is an rvalue reference to astring.- Pros:
Defining a move constructor (a constructor taking an rvalue reference to the class type) makes it possible to move a value instead of copying it. If
v1is astd::vector<string>, for example, then autov2(std::move(v1))will probably just result in some simple pointer manipulation instead of copying a large amount of data. In some cases this can result in a major performance improvement.Rvalue references make it possible to write a generic function wrapper that forwards its arguments to another function, and works whether or not its arguments are temporary objects. (This is sometimes called “perfect forwarding”.)
Rvalue references make it possible to implement types that are movable but not copyable, which can be useful for types that have no sensible definition of copying but where you might still want to pass them as function arguments, put them in containers, etc.
std::moveis necessary to make effective use of some standard-library types, such asstd::unique_ptr.
- Decision:
Use rvalue references to define move constructors and move assignment operators (as described in Copyable and Movable Types) and, in conjunction with
std::forward, to support perfect forwarding. You may usestd::moveto express moving a value from one object to another rather than copying it.
Friends¶
We allow use of friend classes and functions, within reason.
Friends should usually be defined in the same file so that the reader does not have to look in another file to find uses of the private members of a class. A common use of friend is to have a FooBuilder class be a friend of Foo so that it can construct the inner state of Foo correctly, without exposing this state to the world.
Friends extend, but do not break, the encapsulation boundary of a class. In some cases this is better than making a member public when you want to give only one other class access to it. However, most classes should interact with other classes solely through their public members.
Exceptions¶
We use C++ exceptions extensively.
- Pros:
Exceptions allow higher levels of an application to decide how to handle “can’t happen” failures in deeply nested functions, without the obscuring and error-prone bookkeeping of error codes.
Exceptions are used by most other modern languages. Using them in C++ would make it more consistent with Python, Java, and the C++ that others are familiar with.
Some third-party C++ libraries use exceptions, and turning them off internally makes it harder to integrate with those libraries.
Exceptions are the only way for a constructor to fail. We can simulate this with a factory function or an
initialise()method, but these require heap allocation or a new “invalid” state, respectively.Exceptions are really handy in testing frameworks.
- Cons:
When you add a throw statement to an existing function, you must examine all of its transitive callers. Either they must make at least the basic exception safety guarantee, or they must never catch the exception and be happy with the program terminating as a result. For instance, if
f()callsg()callsh(), andhthrows an exception thatfcatches,ghas to be careful or it may not clean up properly.More generally, exceptions make the control flow of programs difficult to evaluate by looking at code: functions may return in places you don’t expect. This causes maintainability and debugging difficulties. You can minimise this cost via some rules on how and where exceptions can be used, but at the cost of more that a developer needs to know and understand.
Exception safety requires both RAII and different coding practices. Lots of supporting machinery is needed to make writing correct exception-safe code easy. Further, to avoid requiring readers to understand the entire call graph, exception-safe code must isolate logic that writes to persistent state into a “commit” phase. This will have both benefits and costs (perhaps where you’re forced to obfuscate code to isolate the commit). Allowing exceptions would force us to always pay those costs even when they’re not worth it.
Turning on exceptions adds data to each binary produced, increasing compile time (probably slightly) and possibly increasing address space pressure.
Decision: On their face, the benefits of using exceptions outweigh the costs, especially in new projects. Especially in a computational project, were we are perfectly happy to terminate if an exception is thrown.
There is an exception to this rule (no pun intended) for Windows code.
noexcept¶
Specify noexcept when it is useful and correct.
- Definition:
The
noexceptspecifier is used to specify whether a function will throw exceptions or not. If an exception escapes from a function markednoexcept, the program crashes viastd::terminate.The
noexceptoperator performs a compile-time check that returns true if an expression is declared to not throw any exceptions.- Pros:
Specifying move constructors as
noexceptimproves performance in some cases, e.g.std::vector<T>::resize()moves rather than copies the objects ifT’s move constructor isnoexcept.Specifying
noexcepton a function can trigger compiler optimisations in environments where exceptions are enabled, e.g. compiler does not have to generate extra code for stack-unwinding, if it knows that no exceptions can be thrown due to anoexceptspecifier.
- Cons:
It’s hard, if not impossible, to undo
noexceptbecause it eliminates a guarantee that callers may be relying on, in ways that are hard to detect.
- Decision:
You should use
noexceptwhen it is useful for performance if it accurately reflects the intended semantics of your function, i.e. that if an exception is somehow thrown from within the function body then it represents a fatal error. You can assume thatnoexcepton move constructors has a meaningful performance benefit. If you think there is significant performance benefit from specifyingnoexcepton some other function, feel free to use it.
Run-Time Type Information (RTTI)¶
When possible, avoid using Run Time Type Information (RTTI).
- Definition:
RTTI allows a programmer to query the C++ class of an object at run time. This is done by use of
typeidordynamic_cast.- Cons:
Querying the type of an object at run-time frequently means a design problem. Needing to know the type of an object at runtime is often an indication that the design of your class hierarchy is flawed.
Undisciplined use of RTTI makes code hard to maintain. It can lead to type-based decision trees or switch statements scattered throughout the code, all of which must be examined when making further changes.
- Pros:
RTTI can be very useful when interacting with duck-typed languages (like python) and when implementing efficient containers with polymorphic interfaces, see, e.g., µSpectre’s
FieldMapimplementation.RTTI can be useful in some unit tests. For example, it is useful in tests of factory classes where the test has to verify that a newly created object has the expected dynamic type. It is also useful in managing the relationship between objects and their mocks.
RTTI is useful when considering multiple abstract objects. Consider
bool Base::Equal(Base* other) = 0; bool Derived::Equal(Base* other) { Derived* that = dynamic_cast<Derived*>(other); if (that == nullptr) { return false; } ... }
- Decision:
RTTI has legitimate uses but is prone to abuse, so you must be careful when using it. You may use it freely in unit tests, but avoid it when possible in other code. In particular, think twice before using RTTI in new code. If you find yourself needing to write code that behaves differently based on the class of an object, consider one of the following alternatives to querying the type:
Virtual methods are the preferred way of executing different code paths depending on a specific subclass type. This puts the work within the object itself.
If the work belongs outside the object and instead in some processing code, consider a double-dispatch solution, such as the Visitor design pattern. This allows a facility outside the object itself to determine the type of class using the built-in type system.
When the logic of a program guarantees that a given instance of a base class is in fact an instance of a particular derived class, then a
dynamic_castmay be used freely on the object. Usually one can use astatic_castas an alternative in such situations.Decision trees based on type are a strong indication that your code is on the wrong track.
if (typeid(*data) == typeid(D1)) { ... } else if (typeid(*data) == typeid(D2)) { ... } else if (typeid(*data) == typeid(D3)) { ...
Code such as this usually breaks when additional subclasses are added to the class hierarchy. Moreover, when properties of a subclass change, it is difficult to find and modify all the affected code segments.
Do not hand-implement an RTTI-like workaround. The arguments against RTTI apply just as much to workarounds like class hierarchies with type tags. Moreover, workarounds disguise your true intent.
Casting¶
Use C++-style casts like static_cast<float>(double_value), or brace initialisation for conversion of arithmetic types like int64 y{int64{1} << 42}. Do not use cast formats like int y{(int)x} or int y{int(x)} (but the latter is okay when invoking a constructor of a class type).
- Definition:
C++ introduced a different cast system from C that distinguishes the types of cast operations.
- Pros:
The problem with C casts is the ambiguity of the operation; sometimes you are doing a conversion (e.g.,
(int)3.5) and sometimes you are doing a cast (e.g.,(int)"hello"). Brace initialisation and C++ casts can often help avoid this ambiguity. Additionally, C++ casts are more visible when searching for them.- Cons:
The C++-style cast syntax is verbose
- Decision:
Do not use C-style casts. Instead, use these C++-style casts when explicit type conversion is necessary.
Use brace initialisation to convert arithmetic types (e.g.
int64{x}). This is the safest approach because code will not compile if conversion can result in information loss. The syntax is also concise.Use
static_castas the equivalent of a C-style cast that does value conversion, when you need to explicitly up-cast a pointer from a class to its superclass, or when you need to explicitly cast a pointer from a superclass to a subclass. In this last case, you must be sure your object is actually an instance of the subclass.Use
const_castto remove theconstqualifier (see Use of const). This indicates a serious design flaw if it happens in µSpectre and is to be considered a bug. Only use this if third-party libraries force you to.Use
reinterpret_castto do unsafe conversions of pointer types to and from integer and other pointer types. Use this only if you know what you are doing and you understand the aliasing issues.
See the RTTI section for guidance on the use of dynamic_cast.
Streams¶
Use streams where appropriate, and stick to “simple” usages. Overload << for streaming only for types representing values, and write only the user-visible value, not any implementation details.
- Definition:
Streams are the standard I/O abstraction in C++, as exemplified by the standard header
<iostream>.- Pros:
The
<<and>>stream operators provide an API for formatted I/O that is easily learned, portable, reusable, and extensible.printf, by contrast, doesn’t even support string, to say nothing of user-defined types, and is very difficult to use portably.printfalso obliges you to choose among the numerous slightly different versions of that function, and navigate the dozens of conversion specifiers.Streams provide first-class support for console I/O via
std::cin,std::cout,std::cerr, andstd::clog. The C APIs do as well, but are hampered by the need to manually buffer the input.- Cons:
Stream formatting can be configured by mutating the state of the stream. Such mutations are persistent, so the behaviour of your code can be affected by the entire previous history of the stream, unless you go out of your way to restore it to a known state every time other code might have touched it. User code can not only modify the built-in state, it can add new state variables and behaviours through a registration system.
It is difficult to precisely control stream output, due to the above issues, the way code and data are mixed in streaming code, and the use of operator overloading (which may select a different overload than you expect).
The streams API is subtle and complex, so programmers must develop experience with it in order to use it effectively.
Resolving the many overloads of
<<is extremely costly for the compiler. When used pervasively in a large code base, it can consume as much as 20% of the parsing and semantic analysis time.
- Decision:
Use streams only when they are the best tool for the job. This is typically the case when the I/O is ad-hoc, local, human-readable, and targeted at other developers rather than end-users. Be consistent with the code around you, and with the code base as a whole; if there’s an established tool for your problem, use that tool instead. In particular, logging libraries are usually a better choice than
std::cerrorstd::clogfor diagnostic output.Overload
<<as a streaming operator for your type only if your type represents a value, and<<writes out a human-readable string representation of that value. Avoid exposing implementation details in the output of<<; if you need to print object internals for debugging, use named functions instead (a method nameddebug_string()is the most common convention).
Preincrement and Predecrement¶
Use prefix form (++i) of the increment and decrement operators with iterators and other template objects.
- Definition:
When a variable is incremented (
++iori++) or decremented (--iori--) and the value of the expression is not used, one must decide whether to pre-increment (decrement) or post-increment (decrement).- Pros:
When the return value is ignored, the “pre” form (
++i) is never less efficient than the “post” form (i++), and is often more efficient. This is because post-increment (or decrement) requires a copy ofito be made, which is the value of the expression. Ifiis an iterator or other non-scalar type, copyingicould be expensive. Since the two types of increment behave the same when the value is ignored, why not just always pre-increment?- Cons:
The tradition developed, in C, of using post-increment when the expression value is not used, especially in for loops. Some find post-increment easier to read, since the “subject” (
i) precedes the “verb” (++), just like in English. This is a dumb tradition and should be abolished.- Decision:
If the return value is ignored, a post-increment (post-decrement) is a bug.
Use of const¶
Use const doggedly whenever it makes is correct. With C++11, constexpr is a better choice for some uses of const.
- Definition:
Declared variables and parameters can be preceded by the keyword
constto indicate the variables are not changed (e.g.,const int foo). Class functions can have theconstqualifier to indicate the function does not change the state of the class member variables (e.g.,class Foo { int Bar(char c) const; };).- Pros:
Easier for people to understand how variables are being used. Allows the compiler to do better type checking, and, conceivably, generate better code. Helps people convince themselves of program correctness because they know the functions they call are limited in how they can modify your variables. Helps people know what functions are safe to use without locks in multi-threaded programs.
constis viral: if you pass aconstvariable to a function, that function must haveconstin its prototype.- Cons:
constcan be problem when calling library functions, and requireconst_cast.- Decision:
const variables, data members, methods and arguments add a level of compile-time type checking; it is better to detect errors as soon as possible. Therefore we strongly recommend that you use
constwhenever it is possible to do so:If a function guarantees that it will not modify an argument passed by reference, the corresponding function parameter should be a reference-to-const (
const T&).Declare methods to be
constwhenever possible. Accessors should almost always beconst. Other methods should beconstif they do not modify any data members, do not call any non-constmethods, and do not return a non-constreference to a data member.Consider making data members
constwhenever they do not need to be modified after construction.
The mutable keyword is allowed but is unsafe when used with threads, so thread safety should be carefully considered first.
Use of constexpr¶
In C++11, use constexpr to define true constants or to ensure constant initialisation.
- Definition:
Some variables can be declared
constexprto indicate the variables are true constants, i.e. fixed at compilation/link time. Some functions and constructors can be declaredconstexprwhich enables them to be used in defining aconstexprvariable.- Pros:
Use of
constexprenables definition of constants with floating-point expressions rather than just literals; definition of constants of user-defined types; and definition of constants with function calls.- Decision:
constexprdefinitions enable a more robust specification of the constant parts of an interface. Useconstexprto specify true constants and the functions that support their definitions. You can useconstexprto force inlining of functions.
Integer Types¶
We do not use the built-in C++ integer types in µSpectre, rather the alias Int. If a part needs a variable of a different size, use a precise-width integer type from <cstdint>, such as int16_t. If your variable represents a value that could ever be greater than or equal to 2³¹ (2GiB), use a 64-bit type such as int64_t. Keep in mind that even if your value won’t ever be too large for an Int, it may be used in intermediate calculations which may require a larger type. When in doubt, choose a larger type.
- Definition:
µSpectre does not specify the size of
Int. Assume it’s 32 bits.- Pros:
Uniformity of declaration.
- Cons:
The sizes of integral types in C++ can vary based on compiler and architecture.
- Decision:
<cstdint>defines types likeint16_t,uint32_t,int64_t, etc. You should always use those in preference to short, unsigned long long and the like, when you need a guarantee on the size of an integer. When appropriate, you are welcome to use standard types likesize_tandpetrify_t.We use
Intvery often, for integers we know are not going to be too big, e.g., loop counters. Use plain oldIntfor such things. You should assume that anIntis at least 32 bits, but don’t assume that it has more than 32 bits. If you need a 64-bit integer type, useint64_toruint64_t.For integers we know can be “big”, use
int64_t.You should not use the unsigned integer types such as
uint32_t, unless there is a valid reason such as representing a bit pattern rather than a number, or you need defined overflow modulo 2ᴺ. In particular, do not use unsigned types to say a number will never be negative. Instead, use assertions for this.If your code is a container that returns a size, be sure to use a type that will accommodate any possible usage of your container. When in doubt, use a larger type rather than a smaller type.
Use care when converting integer types. Integer conversions and promotions can cause undefined behaviour, leading to security bugs and other problems.
On Unsigned Integers
Unsigned integers are good for representing bitfields and modular arithmetic. Because of historical accident, the C++ standard also uses unsigned integers to represent the size of containers - many members of the standards body believe this to be a mistake, but it is effectively impossible to fix at this point. The fact that unsigned arithmetic doesn’t model the behaviour of a simple integer, but is instead defined by the standard to model modular arithmetic (wrapping around on overflow/underflow), means that a significant class of bugs cannot be diagnosed by the compiler. In other cases, the defined behaviour impedes optimisation.
That said, mixing signedness of integer types is responsible for an equally large class of problems. The best advice we can provide: try to use iterators and containers rather than pointers and sizes, try not to mix signedness, and try to avoid unsigned types (except for representing bitfields or modular arithmetic). Do not use an unsigned type merely to assert that a variable is non-negative.
Preprocessor Macros¶
Avoid defining macros, especially in headers; prefer inline functions, enums, and const variables. Do not use macros to define pieces of a C++ API. Be aware that if you do not have a very good reason to submit code with a macro, it will likely be rejected.
Macros mean that the code you see is not the same as the code the compiler sees. This can introduce unexpected behaviour, especially since macros have global scope.
The problems introduced by macros are especially severe when they are used to define pieces of a C++ API, and still more so for public APIs. Every error message from the compiler when developers incorrectly use that interface now must explain how the macros formed the interface. Refactoring and analysis tools have a dramatically harder time updating the interface. As a consequence, we specifically disallow using macros in this way. For example, avoid patterns like:
class WOMBAT_TYPE(Foo) {
// ...
public:
EXPAND_PUBLIC_WOMBAT_API(Foo)
EXPAND_WOMBAT_COMPARISONS(Foo, ==, <)
};
Luckily, macros are not nearly as necessary in C++ as they are in C. Instead of using a macro to inline performance-critical code, use an inline function. Instead of using a macro to store a constant, use a const or constexpr variable. Instead of using a macro to “abbreviate” a long variable name, use a reference. Instead of using a macro to conditionally compile code … well, don’t do that at all (except, of course, for the #define guards to prevent double inclusion of header files, and packages such as MPI). It makes testing much more difficult.
Macros can do things these other techniques cannot, and you do see them in the code base, especially in the lower-level libraries. And some of their special features (like stringifying, concatenation, and so forth) are not available through the language proper. But before using a macro, consider carefully whether there’s a non-macro way to achieve the same result. If you need to use a macro to define an interface, discuss it with the community in an issue <https://gitlab.com/muspectre/muspectre/issues>>`_.
The following usage pattern will avoid many problems with macros; if you use macros, follow it whenever possible:
Don’t define macros in a
.hhfile.
#definemacros right before you use them, and#undefthem right after.Do not just
#undefan existing macro before replacing it with your own; instead, pick a name that’s likely to be unique.Try not to use macros that expand to unbalanced C++ constructs, or at least document that behaviour well.
Prefer not using
##to generate function/class/variable names.
Exporting macros from headers (i.e. defining them in a header without #undefing them before the end of the header) is extremely strongly discouraged. If you do export a macro from a header, it must have a globally unique name. To achieve this, it must be named with a prefix consisting of your project’s namespace name (but upper case).
0 and nullptr/NULL¶
Use 0 for integers, 0. for reals, nullptr for pointers, and '\0' for chars.
For pointers (address values), there is a choice between 0, NULL, and nullptr. µSpectre only accepts nullptr, as this provides type-safety.
Use '\0' for the null character. Using the correct type makes the code more readable.
sizeof¶
Prefer sizeof(varname) to sizeof(type).
Use sizeof(varname) when you take the size of a particular variable. sizeof(varname) will update appropriately if someone changes the variable type either now or later. You may use sizeof(type) for code unrelated to any particular variable, such as code that manages an external or internal data format where a variable of an appropriate C++ type is not convenient.
Struct data;
memset(&data, 0, sizeof(data));
memset(&data, 0, sizeof(Struct));
if (raw_size < sizeof(int)) {
LOG(ERROR) << "compressed record not big enough for count: " << raw_size;
return false;
}
auto¶
Use auto to avoid type names that are noisy, obvious, or unimportant - cases where the type doesn’t aid in clarity for the reader. Continue to use manifest type declarations only when it helps readability or you wish to override the type (important in the context of expression templates, see Eigen C++11 and the auto keyword).
- Pros:
C++ type names can be long and cumbersome, especially when they involve templates or namespaces.
Long type names hinder readability.
When a C++ type name is repeated within a single declaration or a small code region, the repetition hinders readability and breaks the DRY principle.
It is sometimes safer to let the type be specified by the type of the initialisation expression, since that avoids the possibility of unintended copies or type conversions.
Allows the use of universal references
auto &&which allow to write efficient template expression code without sacrificing readability.
- Cons:
Sometimes code is clearer when types are manifest, especially when a variable’s initialisation depends on things that were declared far away. In expressions like:
auto foo = x.add_foo(); auto i = y.Find(key);
it may not be obvious what the resulting types are if the type of
yisn’t very well known, or ifywas declared many lines earlier.Programmers have to understand the difference between
autoandconst auto&or they’ll get copies when they didn’t mean to.
- Decision:
autois highly encouraged when it increases readability and reduces redundant code repetitions, particularly as described below. Not usingautoin these conditions is to be considered a bug. Never initialise anauto-typed variable with a braced initialiser list.
Typical example cases where auto is appropriate:
For iterators and other long/cluttery type names, particularly when the type is clear from context (calls to
find,begin, orendfor instance).When the type is clear from local context (in the same expression or within a few lines). Initialisation of a pointer or smart pointer with calls to
newandstd::make_uniquecommonly falls into this category, as does use ofautoin a range-based loop over a container whose type is spelled out nearby.When the type doesn’t matter because it isn’t being used for anything other than equality comparison.
When iterating over a map with a range-based loop (because it is often assumed that the correct type is
std::pair<KeyType, ValueType>whereas it is actuallystd::pair<const KeyType, ValueType>). This is particularly well paired with local key and value aliases for.firstand.second(often const-ref).for (const auto& item : some_map) { const KeyType& key = item.first; const ValType& value = item.second; // The rest of the loop can now just refer to key and value, // a reader can see the types in question, and we've avoided // the too-common case of extra copies in this iteration. }
Braced Initialiser List¶
You may use braced initialiser lists.
In C++03, aggregate types (arrays and structs with no constructor) could be initialised with braced initialiser lists.
struct Point { int x; int y; };
Point p = {1, 2};
In C++11, this syntax was generalised, and any object type can now be created with a braced initialiser list, known as a braced-init-list in the C++ grammar. Here are a few examples of its use.
// Vector takes a braced-init-list of elements.
std::vector<string> v{"foo", "bar"};
// Basically the same, ignoring some small technicalities.
// You may choose to use either form.
std::vector<string> v = {"foo", "bar"};
// Usable with 'new' expressions.
auto p = new std::vector<string>{"foo", "bar"};
// A map can take a list of pairs. Nested braced-init-lists work.
std::map<int, string> m = {{1, "one"}, {2, "2"}};
// A braced-init-list can be implicitly converted to a return type.
std::vector<int> test_function() { return {1, 2, 3}; }
// Iterate over a braced-init-list.
for (int i : {-1, -2, -3}) {}
// Call a function using a braced-init-list.
void TestFunction2(std::vector<int> v) {}
TestFunction2({1, 2, 3});
A user-defined type can also define a constructor and/or assignment operator that take std::initialiser_list<T>, which is automatically created from braced-init-list:
class MyType {
public:
// std::initialiser_list references the underlying init list.
// It should be passed by value.
MyType(std::initialiser_list<int> init_list) {
for (int i : init_list) append(i);
}
MyType& operator=(std::initialiser_list<int> init_list) {
clear();
for (int i : init_list) append(i);
}
};
MyType m{2, 3, 5, 7};
Finally, brace initialisation can also call ordinary constructors of data types, even if they do not have std::initialiser_list<T> constructors.
double d{1.23};
// Calls ordinary constructor as long as MyOtherType has no
// std::initialiser_list constructor.
class MyOtherType {
public:
explicit MyOtherType(string);
MyOtherType(int, string);
};
MyOtherType m = {1, "b"};
// If the constructor is explicit, you can't use the "= {}" form.
MyOtherType m{"b"};
Never assign a braced-init-list to an auto local variable. In the single element case, what this means can be confusing.
auto d = {1.23}; // d is a std::initialiser_list<double>
auto d = double{1.23}; // Good but weird -- d is a double, not a std::initialiser_list.
See Braced Initialiser List Format for formatting.
Lambda expressions¶
Use lambda expressions where appropriate. Use explicit captures.
- Definition:
Lambda expressions are a concise way of creating anonymous function objects. They’re often useful when passing functions as arguments. For example:
std::sort(v.begin(), v.end(), [](int x, int y) { return Weight(x) < Weight(y); });
They further allow capturing variables from the enclosing scope either explicitly by name, or implicitly using a default capture. Explicit captures require each variable to be listed, as either a value or reference capture:
int weight{3}; int sum{0}; // Captures `weight` by value and `sum` by reference. std::for_each(v.begin(), v.end(), [weight, &sum](int x) { sum += weight * x; });
Default captures implicitly capture any variable referenced in the lambda body, including this if any members are used:
const std::vector<int> lookup_table = ...; std::vector<int> indices = ...; // Captures `lookup_table` by reference, sorts `indices` by the value // of the associated element in `lookup_table`. std::sort(indices.begin(), indices.end(), [&](int a, int b) { return lookup_table[a] < lookup_table[b]; });
Lambdas were introduced in C++11 along with a set of utilities for working with function objects, such as the polymorphic wrapper
std::function.- Pros:
Lambdas are much more concise than other ways of defining function objects to be passed to STL algorithms, which can be a readability improvement.
Appropriate use of default captures can remove redundancy and highlight important exceptions from the default.
Lambdas,
std::function, andstd::bindcan be used in combination as a general purpose callback mechanism; they make it easy to write functions that take bound functions as arguments.
- Cons:
Variable capture in lambdas can be a source of dangling-pointer bugs, particularly if a lambda escapes the current scope.
Default captures by value can be misleading because they do not prevent dangling-pointer bugs. Capturing a pointer by value doesn’t cause a deep copy, so it often has the same lifetime issues as capture by reference. This is especially confusing when capturing
thisby value, since the use ofthisis often implicit.It’s possible for use of lambdas to get out of hand; very long nested anonymous functions can make code harder to understand.
- Decision:
Use lambda expressions where appropriate, with formatting as described below.
Use explicit captures if the lambda may escape the current scope. For example, instead of:
{ Foo foo; ... executor->schedule([&] { frobnicate(foo); }) ... } // BAD! The fact that the lambda makes use of a reference to `foo` and // possibly `this` (if `frobnicate` is a member function) may not be // apparent on a cursory inspection. If the lambda is invoked after // the function returns, that would be bad, because both `foo` // and the enclosing object could have been destroyed.
prefer to write:
{ Foo foo; ... executor->schedule([&foo] { frobnicate(foo); }) ... } // BETTER - The compile will fail if `frobnicate` is a member // function, and it's clearer that `foo` is dangerously captured by // reference.
Do not usese default capture by reference (
[&]).Do not use default capture by value (
[=]).Keep unnamed lambdas short. If a lambda body is more than maybe five lines long, prefer to give the lambda a name, or to use a named function instead of a lambda.
Specify the return type of the lambda explicitly if that will make it more obvious to readers, as with
auto.
Template metaprogramming¶
Template metaprogramming is our tool to obtain both generic and efficient code. It can be complicated, but efficiency is the top priority in the core of µSpectre.
- Definition:
Template metaprogramming refers to a family of techniques that exploit the fact that the C++ template instantiation mechanism is Turing complete and can be used to perform arbitrary compile-time computation in the type domain.
- Pros:
Template metaprogramming allows extremely flexible interfaces that are type safe and high performance. Facilities like the Boost unit test framework,
std::tuple,std::function, andBoost.Spiritwould be impossible without it.- Cons:
The techniques used in template metaprogramming are often obscure to anyone but language experts. Code that uses templates in complicated ways is demanding to read, and is hard to debug.
Template metaprogramming often leads to extremely poor compiler time error messages: even if an interface is simple, the complicated implementation details become visible when the user does something wrong.
Template metaprogramming interferes with large scale refactoring by making the job of refactoring tools harder. First, the template code is expanded in multiple contexts, and it’s hard to verify that the transformation makes sense in all of them. Second, some refactoring tools work with an AST that only represents the structure of the code after template expansion. It can be difficult to automatically work back to the original source construct that needs to be rewritten.
- Decision:
Template metaprogramming sometimes allows cleaner and easier-to-use interfaces than would be possible without it. It’s best used in a small number of low level components where the extra maintenance burden is spread out over a large number of uses (i.e., the core of µSpectre, e.g.
MaterialMuSpectreand the data structures).
If you use template metaprogramming, you should expect to put considerable effort into minimising and isolating the complexity. You should hide metaprogramming as an implementation detail whenever possible, so that user-facing headers are readable, and you should make sure that tricky code is especially well commented. You should carefully document how the code is used, and you should say something about what the “generated” code looks like. Pay extra attention to the error messages that the compiler emits when users make mistakes. The error messages are part of your user interface, and your code should be tweaked as necessary so that the error messages are understandable and actionable from a user point of view.
Boost¶
We try to depend on Boost as little as possible. The core library should not at all depend on Boost, while the tests use the Boost unit test framework. There is one exception: For users with ancient compilers, Boost is used to emulate std::optional. Do not add Boost dependencies.
- Definition:
The Boost library collection is a popular collection of peer-reviewed, free, open-source C++ libraries.
- Pros:
Boost code is generally very high-quality, is widely portable, and fills many important gaps in the C++ standard library, such as type traits and better binders.
- Cons:
Boost can be tricky to install on certain systems
C++14¶
Use libraries and language extensions from C++14 when appropriate.
C++14 contains significant improvements both to the language and libraries.
Nonstandard Extensions¶
Nonstandard extensions to C++ may not be used unless needed to fix compiler bugs.
Compilers support various extensions that are not part of standard C++. Such extensions include GCC’s __attribute__.
- Cons:
Nonstandard extensions do not work in all compilers. Use of nonstandard extensions reduces portability of code.
Even if they are supported in all targeted compilers, the extensions are often not well-specified, and there may be subtle behaviour differences between compilers.
Nonstandard extensions add to the language features that a reader must know to understand the code.
- Decision:
Do not use nonstandard extensions.
Aliases¶
Public aliases are for the benefit of an API’s user, and should be clearly documented.
- Definition:
You can create names that are aliases of other entities:
template<class Param> using Bar = Foo<Param>; using other_namespace::Foo;
In µSpectre, aliases are created with the
usingkeyword and never withtypedef, because it provides a more consistent syntax with the rest of C++ and works with templates.Like other declarations, aliases declared in a header file are part of that header’s public API unless they’re in a function definition, in the private portion of a class, or in an explicitly-marked internal namespace. Aliases in such areas or in
.ccfiles are implementation details (because client code can’t refer to them), and are not restricted by this rule.- Pros:
Aliases can improve readability by simplifying a long or complicated name.
Aliases can reduce duplication by naming in one place a type used repeatedly in an API, which might make it easier to change the type later.
- Cons:
When placed in a header where client code can refer to them, aliases increase the number of entities in that header’s API, increasing its complexity.
Clients can easily rely on unintended details of public aliases, making changes difficult.
It can be tempting to create a public alias that is only intended for use in the implementation, without considering its impact on the API, or on maintainability.
Aliases can create risk of name collisions
Aliases can reduce readability by giving a familiar construct an unfamiliar name
Type aliases can create an unclear API contract: it is unclear whether the alias is guaranteed to be identical to the type it aliases, to have the same API, or only to be usable in specified narrow ways
- Decision:
Don’t put an alias in your public API just to save typing in the implementation; do so only if you intend it to be used by your clients.
When defining a public alias, document the intent of the new name. This lets the user know whether they can treat the types as substitutable or whether more specific rules must be followed, and can help the implementation retain some degree of freedom to change the alias.
Don’t put namespace aliases in your public API. (See also Namespaces).
For example, these aliases document how they are intended to be used in client code:
namespace mynamespace { // Used to store field measurements. DataPoint may change from Bar* to some internal type. // Client code should treat it as an opaque pointer. using DataPoint = foo::Bar*; // A set of measurements. Just an alias for user convenience. using TimeSeries = std::unordered_set<DataPoint, std::hash<DataPoint>, DataPointComparator>; } // namespace mynamespace
These aliases don’t document intended use, and half of them aren’t meant for client use:
namespace mynamespace { // Bad: none of these say how they should be used. using DataPoint = foo::Bar*; using std::unordered_set; // Bad: just for local convenience using std::hash; // Bad: just for local convenience typedef unordered_set<DataPoint, hash<DataPoint>, DataPointComparator> TimeSeries; } // namespace mynamespace
However, local convenience aliases are fine in function definitions, private sections of classes, explicitly marked internal namespaces, and in
.ccfiles:// In a ``.cc`` file using foo::Bar;
Naming¶
The most important consistency rules are those that govern naming. The style of a name immediately informs us what sort of thing the named entity is: a type, a variable, a function, a constant, a macro, etc., without requiring us to search for the declaration of that entity. The pattern-matching engine in our brains relies a great deal on these naming rules.
Naming rules are pretty arbitrary, but we feel that consistency is more important than individual preferences in this area, so regardless of whether you find them sensible or not, the rules are the rules.
General Naming Rules¶
Names should be descriptive; avoid abbreviation.
Give as descriptive a name as possible, within reason. Do not worry about saving horizontal space as it is far more important to make your code immediately understandable by a new reader. Do not use abbreviations that are ambiguous or unfamiliar to readers outside your project, and do not abbreviate by deleting letters within a word. Abbreviations that would be familiar to someone outside your project with relevant domain knowledge are OK. As a rule of thumb, an abbreviation is probably OK if it’s listed in Wikipedia.
A few good examples:
int price_count_reader; // No abbreviation.
int nb_params; // "nb" is a widespread convention.
int nb_dns_connections; // Most people know what "DNS" stands for.
int lstm_size; // "LSTM" is a common machine learning abbreviation.
A few bad examples
int n; // Meaningless.
int nerr; // Ambiguous abbreviation.
int n_comp_conns; // Ambiguous abbreviation.
int wgc_connections; // Only your group knows what this stands for.
int pc_reader; // Lots of things can be abbreviated "pc".
int cstmr_id; // Deletes internal letters.
FooBarRequestInfo fbri; // Not even a word.
Note that certain universally-known abbreviations are OK, such as i for an iteration variable and T for a template parameter.
For some symbols, this style guide recommends names to start with a capital letter and to have a capital letter for each new word (a.k.a. “CamelCase”). When abbreviations appear in such names, prefer to capitalise every letter of the abbreviation (i.e. FFTEngine, not FftEngine).
Template parameters should follow the naming style for their category: type template parameters should follow the rules for type names, and non-type template parameters should follow the rules for constexpr variable names.
File Names¶
Filenames should be all lowercase and can include underscores (_). File names should indicate their content.
Examples of acceptable file names:
my_useful_class.cc # implementation of MyUsefulClass
my_useful_class.hh # interface and inlines of MyUsefulClass
fft_utils.hh # declarations (header) for a bunch of FFT-related tools
test_my_useful_class.cc // unittests for MyUsefulClass
C++ files should end in .cc and header files should end in .hh (see also the section on self-contained headers).
Do not use filenames that already exist in /usr/include or widely used libraries, such as db.hh.
In general, make your filenames very specific. For example, use http_server_logs.hh rather than logs.hh. A very common case is to have a pair of files called, e.g., foo_bar.hh and foo_bar.cc, defining a class called FooBar.
Inline functions must be in a .hh file. If your inline functions are very short, they should go directly into your .hh file.
Type Names¶
Type names start with a capital letter and have a capital letter for each new word (CamelCase), with no underscores: MyExcitingClass, MyExcitingEnum.
The names of all types — classes, structs, type aliases, enums, and type template parameters — have the same naming convention. Type names should start with a capital letter and have a capital letter for each new word. No underscores. For example:
// classes and structs
class UrlTable { ...
class UrlTableTester { ...
struct UrlTableProperties { ...
// using aliases
using PropertiesMap_t = hash_map<UrlTableProperties *, string>;
// enums
enum UrlTableErrors { ...
- There are two classes of very useful exception to above rules:
When using aliases, please append
_tfor alias types_ptrfor alias (smart) pointers and_reffor alias references andstd::reference_wrappers.In the specific context of type manipulations using the STL’s type traits, it can help readability to follow the STL’s convention of lowercase
type_names_with_undenscores_t.
Variable Names¶
The names of variables (including function parameters) and data members are all lowercase, with underscores between words. For instance: a_local_variable, a_struct_data_member, this->a_class_data_member. Use class members exclusively with explicit mention of the this pointer.
Common Variable names
For example:
string table_name; // OK - uses underscore.
string tablename; // Bad - missing underscore.
string tableName; // Bad - mixed case.
struct and class Data Members¶
Data members of structs and classes, both static and non-static, are named like ordinary nonmember variables.
class TableInfo {
...
private:
string unique_name; // OK - underscore at end.
static Field_t<FieldCollection> gradient; // OK.
string tablename; // Bad - missing underscore.
};
See Structs vs. Classes for a discussion of when to use a struct versus a class.
constexpr and const Names¶
Variables declared constexpr and non-class template parameters are CamelCase, const are named like regular variables.
Function Names¶
Regular functions and methods are named like variables (lowercase name_with_underscore).
make_field()
get_nb_components()
compute_stresses()
Distinguish (member) functions that compute something at non-trivial cost from simple accessors to internal variables, and constexpr static accessors:
compute_stresses() // not an accessor, does actual work
get_nb_components() // simple accessor
sdim() // constexpr compile-time access
Namespace Names¶
The main namespace is muSpectre. All subordinate namespaces are CamelCase. Avoid collisions between nested namespaces and well-known top-level namespaces. If a namespace is only used to hide unnecessary internal complications, put it in namespace internal or namespace *_internal to indicate that these are implementation details that the user does not have to bother with.
Keep in mind that the rule against abbreviated names applies to namespaces just as much as variable names. Code inside the namespace seldom needs to mention the namespace name, so there’s usually no particular need for abbreviation anyway.
Avoid nested namespaces that match well-known top-level namespaces. Collisions between namespace names can lead to surprising build breaks because of name lookup rules. In particular, do not create any nested std namespaces.
Enumerator Names¶
Enumerators (for both scoped and unscoped enums) should be named like constexpr variables (CamelCase).
Preferably, the individual enumerators should be named like constants. However, it is also acceptable to name them like macros. The enumeration name, UrlTableErrors (and AlternateUrlTableErrors), is a type, and therefore mixed case.
//! Material laws can declare which type of strain measure they require and
//! µSpectre will provide it
enum class StrainMeasure {
Gradient, //!< placement gradient (δy/δx)
Infinitesimal, //!< small strain tensor .5(∇u + ∇uᵀ)
GreenLagrange, //!< Green-Lagrange strain .5(Fᵀ·F - I)
Biot, //!< Biot strain
Log, //!< logarithmic strain
Almansi, //!< Almansi strain
RCauchyGreen, //!< Right Cauchy-Green tensor
LCauchyGreen, //!< Left Cauchy-Green tensor
no_strain_ //!< only for triggering static_assert
};
Note that the last case, StrainMeasure::no_strain_ is deliberately not named like an enum, to indicate that it is an invalid state;
Macro Names¶
You’re not really going to define a macro, are you? If you do, they’re like this: MY_MACRO_THAT_SCARES_SMALL_CHILDREN_AND_ADULTS_ALIKE.
Please see the description of macros; in general macros should not be used. However, if they are absolutely needed, then they should be named with all capitals and underscores. Be ready to argue the need for a macro in your submission, and prepare yourself for rejection if you do not have an overwhelmingly convincing reason.
#define ROUND(x) ...
#define PI_ROUNDED 3.0
Exceptions to Naming Rules¶
Exceptions are classes and as such follow the Type Names rules (CamelCase), but additionally end in Error, e.g., ProjectionError.
Formatting¶
Coding style and formatting are pretty arbitrary, but a project is much easier to follow if everyone uses the same style. Individuals may not agree with every aspect of the formatting rules, and some of the rules may take some getting used to, but it is important that all project contributors follow the style rules so that they can all read and understand everyone’s code easily.
To help you format code correctly, Google has created a settings file for emacs.
Line Length¶
Each line of text in your code should be at most 80 characters long.
We recognise that this rule is controversial, but so much existing code already adheres to it, and we feel that consistency is important.
- Pros:
Those who favour this rule argue that it is rude to force them to resize their windows and there is no need for anything longer. Some folks are used to having several code windows side-by-side, and thus don’t have room to widen their windows in any case. People set up their work environment assuming a particular maximum window width, and 80 columns has been the traditional standard. Why change it?
- Cons:
Proponents of change argue that a wider line can make code more readable. The 80-column limit is an hidebound throwback to 1960s mainframes; modern equipment has wide screens that can easily show longer lines.
- Decision:
80 characters is the maximum.
- Exception:
Comment lines can be longer than 80 characters if it is not feasible to split them without harming readability, ease of cut and paste or auto-linking – e.g. if a line contains an example command or a literal URL longer than 80 characters.
- Exception:
A raw-string literal may have content that exceeds 80 characters. Except for test code, such literals should appear near the top of a file.
- Exception:
An
#includestatement with a long path may exceed 80 columns.- Exception:
You needn’t be concerned about header guards that exceed the maximum length.
Non-ASCII Characters¶
In comments and human-readable names in strings, non-ASCII characters should be used where they help readability, and must use UTF-8 formatting, e.g.
/**
* verification of resultant strains: subscript ₕ for hard and ₛ
* for soft, Nₕ is nb_lays and Nₜₒₜ is nb_grid_pts, k is contrast
*
* Δl = εl = Δlₕ + Δlₛ = εₕlₕ+εₛlₛ
* => ε = εₕ Nₕ/Nₜₒₜ + εₛ (Nₜₒₜ-Nₕ)/Nₜₒₜ
*
* σ is constant across all layers
* σₕ = σₛ
* => Eₕ εₕ = Eₛ εₛ
* => εₕ = 1/k εₛ
* => ε / (1/k Nₕ/Nₜₒₜ + (Nₜₒₜ-Nₕ)/Nₜₒₜ) = εₛ
*/
constexpr Real factor{1/contrast * Real(nb_lays)/nb_grid_pts[0]
+ 1.-nb_lays/Real(nb_grid_pts[0])};
template <Dim_t DimS, Dim_t DimM>
MaterialHyperElastoPlastic1<DimS, DimM>::
MaterialHyperElastoPlastic1(std::string name, Real young, Real poisson,
Real tau_y0, Real H)
: Parent{name},
plast_flow_field("cumulated plastic flow εₚ", this->internal_fields),
F_prev_field("Previous placement gradient Fᵗ", this->internal_fields),
be_prev_field("Previous left Cauchy-Green deformation bₑᵗ",
this->internal_fields),
young{young}, poisson{poisson},
lambda{Hooke::compute_lambda(young, poisson)},
mu{Hooke::compute_mu(young, poisson)},
K{Hooke::compute_K(young, poisson)},
tau_y0{tau_y0}, H{H},
// the factor .5 comes from equation (18) in Geers 2003
// (https://doi.org/10.1016/j.cma.2003.07.014)
C{0.5*Hooke::compute_C_T4(lambda, mu)},
internal_variables{F_prev_field.get_map(), be_prev_field.get_map(),
plast_flow_field.get_map()}
{}
You shouldn’t use the C++11 char16_t and char32_t character types, since they’re for non-UTF-8 text. For similar reasons you also shouldn’t use wchar_t.
Spaces vs. Tabs¶
Use only spaces, and indent 2 spaces at a time.
We use spaces for indentation. Do not use tabs in your code. You should set your editor to emit spaces when you hit the tab key.
Function Declarations and Definitions¶
Return type on the same line as function name, parameters on the same line if they fit. Wrap parameter lists which do not fit on a single line as you would wrap arguments in a function call.
Functions look like this:
ReturnType ClassName::function_name(Type par_name1, Type par_name2) {
do_something();
}
If you have too much text to fit on one line:
ReturnType ClassName::really_long_function_name(Type par_name1,
Type par_name2,
Type par_name3) {
do_something();
}
or if you cannot fit even the first parameter, be reasonable, in the spirit of readability:
template<class FieldCollection, class EigenArray, class EigenConstArray,
class EigenPlain, Map_t map_type, bool ConstField>
typename MatrixLikeFieldMap<FieldCollection, EigenArray, EigenConstArray,
EigenPlain, map_type, ConstField>::const_reference
MatrixLikeFieldMap<FieldCollection, EigenArray, EigenConstArray, EigenPlain,
map_type, ConstField>::
operator[](const Ccoord & ccoord) const{
size_t index{};
index = this->collection.get_index(ccoord);
return const_reference(this->get_ptr_to_entry(std::move(index)));
}
Some points to note:
Choose good parameter names.
If you cannot fit the return type and the function name on a single line, break between them.
If you break after the return type of a function declaration or definition, do not indent.
There is never a space between the function name and the open parenthesis.
There is never a space between the parentheses and the parameters.
The open curly brace is always on the end of the last line of the function declaration, not the start of the next line.
The close curly brace is either on the last line by itself or on the same line as the open curly brace.
There should be a space between the close parenthesis and the open curly brace.
All parameters should be aligned if possible.
Default indentation is 2 spaces.
Unused parameters that might not be obvious must comment out the variable name in the function definition:
class Shape {
public:
virtual void rotate(double radians) = 0;
};
class Circle : public Shape {
public:
void rotate(double radians) override;
};
void Circle::rotate(double /*radians*/) {}
// Bad - if someone wants to implement later, it's not clear what the
// variable means.
void Circle::rotate(double) {}
Attributes, and macros that expand to attributes, appear at the very beginning of the function declaration or definition, before the return type:
Lambda Expressions¶
Format parameters and bodies as for any other function, and capture lists like other comma-separated lists.
For by-reference captures, do not leave a space between the ampersand (&) and the variable name.
int x = 0;
auto x_plus_n = [&x](int n) -> int { return x + n; }
Short lambdas may be written inline as function arguments.
std::set<int> blacklist = {7, 8, 9};
std::vector<int> digits = {3, 9, 1, 8, 4, 7, 1};
digits.erase(std::remove_if(digits.begin(), digits.end(), [&blacklist](int i) {
return blacklist.find(i) != blacklist.end();
}),
digits.end());
Function Calls¶
Either write the call all on a single line, wrap the arguments at the parenthesis, or use common sense to help readability. In the absence of other considerations, use the minimum number of lines, including placing multiple arguments on each line where appropriate.
Function calls have the following format:
result = do_something(argument1, argument2, argument3);
If the arguments do not all fit on one line, they should be broken up onto multiple lines, with each subsequent line aligned with the first argument. Do not add spaces after the open parenthesis or before the close parenthesis:
result = do_something(averyveryveryverylongargument1,
argument2, argument3);
Arguments may optionally all be placed on subsequent lines.
if (...) {
...
...
if (...) {
bool result = do_something
(argument1, argument2,
argument3, argument4);
...
}
Put multiple arguments on a single line to reduce the number of lines necessary for calling a function unless there is a specific readability problem. Some find that formatting with strictly one argument on each line is more readable and simplifies editing of the arguments. However, we prioritise for the reader over the ease of editing arguments, and most readability problems are better addressed with the following techniques.
If having multiple arguments in a single line decreases readability due to the complexity or confusing nature of the expressions that make up some arguments, try creating variables that capture those arguments in a descriptive name:
int my_heuristic{scores[x] * y + bases[x]};
result = do_something(my_heuristic, x, y, z);
Or put the confusing argument on its own line with an explanatory comment:
result = do_something(scores[x] * y + bases[x], // Score heuristic.
x, y, z);
If there is still a case where one argument is significantly more readable on its own line, then put it on its own line. The decision should be specific to the argument which is made more readable rather than a general policy.
Sometimes arguments form a structure that is important for readability. In those cases, feel free to format the arguments according to that structure:
// Transform the widget by a 3x3 matrix.
my_widget.transform(x1, x2, x3,
y1, y2, y3,
z1, z2, z3);
Braced Initialiser List Format¶
Format a braced initialiser list exactly like you would format a function call in its place.
If the braced list follows a name (e.g. a type or variable name), format as if the {} were the parentheses of a function call with that name. If there is no name, assume a zero-length name.
// Examples of braced init list on a single line.
return {foo, bar};
function_call({foo, bar});
std::pair<int, int> p{foo, bar};
// When you have to wrap.
some_function(
{"assume a zero-length name before {"},
some_other_function_parameter);
SomeType variable{
some, other, values,
{"assume a zero-length name before {"},
SomeOtherType{
"Very long string requiring the surrounding breaks.",
some, other values},
SomeOtherType{"Slightly shorter string",
some, other, values}};
SomeType variable{
"This is too long to fit all in one line"};
MyType m = { // Here, you could also break before {.
superlongvariablename1,
superlongvariablename2,
{short, interior, list},
{interiorwrappinglist,
interiorwrappinglist2}};
Conditionals¶
Prefer no spaces inside parentheses. The if and else keywords belong on separate lines.
if (condition) { // no spaces inside parentheses
... // 2 space indent.
} else if (...) { // The else goes on the same line as the closing brace.
...
} else {
...
}
Note that in all cases you must have a space between the if and the open parenthesis. You must also have a space between the close parenthesis and the curly brace.
if(condition) { // Bad - space missing after IF.
if (condition){ // Bad - space missing before {.
if(condition){ // Doubly bad.
if (condition) { // Good - proper space after IF and before {.
Short conditional statements may be written on one line if this enhances readability. You may use this only when the line is brief and the statement does not use the else clause. You must still use curly braces, as they exclude a particularly dumb class of bugs.
if (x == kFoo) {return new Foo()};
if (x == kBar) {return new Bar()};
This is not allowed when the if statement has an else:
// Not allowed - IF statement on one line when there is an ELSE clause
if (x) {do_this()};
else {do_that()};
Loops and Switch Statements¶
Switch statements must use braces for blocks. Annotate non-trivial fall-through between cases. Empty loop bodies should use {continue;}.
case blocks in switch statements have curly braces which should be placed as shown below.
If not conditional on an enumerated value, switch statements should always have a default case (in the case of an enumerated value, the compiler will warn you if any values are not handled). If the default case should never execute, treat this as an error. For example:
switch (form) {
case Formulation::finite_strain: {
return StrainMeasure::Gradient;
break;
}
case Formulation::small_strain: {
return StrainMeasure::Infinitesimal;
break;
}
default:
return StrainMeasure::no_strain_;
break;
}
Braces are required even for single-statement loops.
for (int i = 0; i < kSomeNumber; ++i)
std::cout << "I love you" << std::endl; // Bad!
for (int i = 0; i < kSomeNumber; ++i) {
std::cout << "I take it back" << std::endl;
} // Good!
Pointer and Reference Expressions¶
No spaces around period or arrow. Pointer operators may have trailing spaces.
The following are examples of correctly-formatted pointer and reference expressions:
x = *p;
x = * p; // also ok
p = &x;
p = & x;
x = r.y;
x = r->y;
Note that:
There are no spaces around the period or arrow when accessing a member.
Pointer operators have no space after the
*or&.
Boolean Expressions¶
When you have a boolean expression that is longer than the standard line length, be consistent in how you break up the lines.
In this example, the logical AND operator is always at the end of the lines:
if (this_one_thing > this_other_thing &&
a_third_thing == a_fourth_thing &&
yet_another && last_one) {
...
}
Note that when the code wraps in this example, both of the && logical AND operators are at the end of the line. This is more common, though wrapping all operators at the beginning of the line is also allowed. Feel free to insert extra parentheses judiciously because they can be very helpful in increasing readability when used appropriately.
Return Values¶
Do not needlessly surround the return expression with parentheses.
Use parentheses in return expr; only where you would use them in x = expr;.
return result; // No parentheses in the simple case.
// Parentheses OK to make a complex expression more readable.
return (some_long_condition &&
another_condition);
return (value); // You wouldn't write var = (value);
return(result); // return is not a function!
Variable and Array Initialisation¶
Use {} when possible, () when necessary, avoid =.
int x(3.5);
int x{3};
string name{"Some Name"};
string name("Some Name"); // could have used non-narrowing {}
int x = 3; // could have used non-narrowing {}
string name = "Some Name"; // could have used non-narrowing {}
Be careful when using a braced initialisation list {...} on a type with an std::initialiser_list constructor. A nonempty braced-init-list prefers the std::initialiser_list constructor whenever possible. Note that empty braces {} are special, and will call a default constructor if available. To force the non-std::initialiser_list constructor, use parentheses instead of braces.
std::vector<int> v(100, 1); // A vector containing 100 items: All 1s.
std::vector<int> v{100, 1}; // A vector containing 2 items: 100 and 1.
Also, the brace form prevents narrowing of integral types. This can prevent some types of programming errors.
int pi(3.14); // OK -- pi == 3.
int pi{3.14}; // Compile error: narrowing conversion.
Preprocessor Directives¶
The hash mark that starts a preprocessor directive should always be at the beginning of the line.
Even when preprocessor directives are within the body of indented code, the directives should start at the beginning of the line.
// Good - directives at beginning of line
if (lopsided_score) {
#if DISASTER_PENDING // Correct -- Starts at beginning of line
DropEverything();
# if NOTIFY // OK but not required -- Spaces after #
NotifyClient();
# endif
#endif
BackToNormal();
}
// Bad - indented directives
if (lopsided_score) {
#if DISASTER_PENDING // Wrong! The "#if" should be at beginning of line
DropEverything();
#endif // Wrong! Do not indent "#endif"
BackToNormal();
}
Class Format¶
Sections in public, protected and private order, each unindented.
The basic format for a class definition (lacking the comments, see Class Comments for a discussion of what comments are needed) is:
class MyClass : public OtherClass {
public: // Note the 1 space indent!
MyClass(); // Regular 2 space indent.
explicit MyClass(int var);
~MyClass() {}
void some_function();
void some_function_that_does_nothing() {
}
void set_some_var(int var) { some_var_ = var; }
int some_var() const { return some_var_; }
protected:
bool SomeInternalFunction();
int some_var_;
int some_other_var_;
};
Things to note:
Any base class name should be on the same line as the subclass name, subject to the 80-column limit.
The
public:,protected:, andprivate:keywords should not be indented.Except for the first instance, these keywords should be preceded by a blank line. This rule is optional in small classes.
Do not leave a blank line after these keywords.
The public section should be first, followed by the protected and finally the private section.
See Declaration Order for rules on ordering declarations within each of these sections.
Constructor Initialiser Lists¶
Constructor initialiser lists can be all on one line or with subsequent lines indented four spaces.
The acceptable formats for initialiser lists are:
// wrap before the colon and indent 2 spaces:
MyClass::MyClass(int var)
:some_var_(var), some_other_var_(var + 1) {
do_something();
}
// When the list spans multiple lines, put each member on its own line
// and align them:
MyClass::MyClass(int var)
:some_var_(var), // 4 space indent
some_other_var_(var + 1) { // lined up
do_something();
}
// As with any other code block, the close curly can be on the same
// line as the open curly, if it fits.
MyClass::MyClass(int var)
:some_var_(var) {}
Namespace Formatting¶
The contents of namespaces are indented normally.
Namespaces add an extra level of indentation. For example, use:
namespace {
void foo() { // Correct. Extra indentation within namespace.
...
}
} // namespace
Indent within a namespace:
namespace {
// Wrong! Not indented when it should not be.
void foo() {
...
}
} // namespace
When declaring nested namespaces, put each namespace on its own line.
namespace foo {
namespace bar {
Horizontal Whitespace¶
Use of horizontal whitespace depends on location. Never put trailing whitespace at the end of a line.
General¶
void f(bool b) { // Open braces should always have a space before them.
...
int i{0}; // Semicolons usually have no space before them.
// Spaces inside braces for braced-init-list are optional. If you use them,
// put them on both sides!
int x[] = { 0 };
int x[] = {0};
// Spaces after the colon in inheritance and initialiser lists.
class Foo: public Bar {
public:
// For inline function implementations, put spaces between the braces
// and the implementation itself.
Foo(int b) : Bar(), baz_(b) {} // No spaces inside empty braces.
void Reset() { baz_ = 0; } // Spaces separating braces from implementation.
...
Adding trailing whitespace can cause extra work for others editing the same file, when they merge, as can removing existing trailing whitespace. So: Don’t introduce trailing whitespace. Remove it if you’re already changing that line, or do it in a separate clean-up operation (preferably when no-one else is working on the file).
Loops and Conditionals¶
if (b) { // Space after the keyword in conditions and loops.
} else { // Spaces around else.
}
while (test) {} // There is usually no space inside parentheses.
switch (i) {
for (int i = 0; i < 5; ++i) {
// Loops and conditions may have spaces inside parentheses, but this
// is rare. Be consistent.
switch ( i ) {
if ( test ) {
for ( int i{0}; i < 5; ++i ) {
// For loops always have a space after the semicolon. They may have a space
// before the semicolon, but this is rare.
for ( ; i < 5 ; ++i) {
...
// Range-based for loops always have a space before and after the colon.
for (auto x : counts) {
...
}
switch (i) {
case 1: // No space before colon in a switch case.
...
case 2: break; // Use a space after a colon if there's code after it.
Operators¶
// Assignment operators always have spaces around them.
x = 0;
// Other binary operators usually have spaces around them, but it's
// OK to remove spaces around factors. Parentheses should have no
// internal padding.
v = w * x + y / z;
v = w*x + y/z;
v = w * (x + z);
// No spaces separating unary operators and their arguments.
x = -5;
++x;
if (x && !y)
...
Templates and Casts¶
// No spaces inside the angle brackets (< and >), before
// <, or between >( in a cast
std::vector<string> x;
y = static_cast<char*>(x);
// Spaces between type and pointer are OK, but be consistent.
std::vector<char *> x;
Vertical Whitespace¶
Minimise use of vertical whitespace.
This is more a principle than a rule: don’t use blank lines when you don’t have to. In particular, don’t put more than one or two blank lines between functions, resist starting functions with a blank line, don’t end functions with a blank line, and be discriminating with your use of blank lines inside functions.
The basic principle is: The more code that fits on one screen, the easier it is to follow and understand the control flow of the program. Of course, readability can suffer from code being too dense as well as too spread out, so use your judgement. But in general, minimise use of vertical whitespace.
Some rules of thumb to help when blank lines may be useful:
Blank lines at the beginning or end of a function very rarely help readability.
Blank lines inside a chain of if-else blocks may well help readability.
Exceptions to the Rules¶
The coding conventions described above are mandatory. However, like all good rules, these sometimes have exceptions, which we discuss here.
Existing Non-conformant Code¶
You may diverge from the rules when dealing with code that does not conform to this style guide.
If you find yourself modifying code that was written to specifications other than those presented by this guide, you may have to diverge from these rules in order to stay consistent with the local conventions in that code. If you are in doubt about how to do this, ask the original author or the person currently responsible for the code. Remember that consistency includes local consistency, too.
Windows Code¶
Just kidding.
Parting Words¶
Use common sense and BE CONSISTENT.
If you are editing code, take a few minutes to look at the code around you and determine its style. If they use spaces around their if clauses, you should, too. If their comments have little boxes of stars around them, make your comments have little boxes of stars around them too.
The point of having style guidelines is to have a common vocabulary of coding so people can concentrate on what you are saying, rather than on how you are saying it. We present global style rules here so people know the vocabulary. But local style is also important. If code you add to a file looks drastically different from the existing code around it, the discontinuity throws readers out of their rhythm when they go to read it. Try to avoid this.
OK, enough writing about writing code; the code itself is much more interesting. Have fun!
Python Coding Style¶
µSpectre is a C++ project with a thin Python wrapping. Try to follow the spirit of the C++ Coding Style and Convention, as far as it fits into pep8. in case of conflict, follow pep8
References¶
Hunt (2000) A. Hunt. The pragmatic programmer : from journeyman to master. Addison-Wesley, Reading, Mass, 2000. ISBN 978-0-2016-1622-4.
Meyers (2014) Scott Meyers. Effective Modern C++, O’Reilly Media, November 2014, ISBN 978-1491903995
Comments¶
Though a pain to write, comments are absolutely vital to keeping our code readable. The following rules describe what you should comment and where. But remember: while comments are very important, the best code is self-documenting. Giving sensible names to types and variables is much better than using obscure names that you must then explain through comments.
When writing your comments, write for your audience: the next contributor who will need to understand your code. Be generous — the next one may be you!
Comment Style¶
Use either the
//or/* ... */syntax for comments that are only relevant within their context (local comments for the reader/maintainer of your code)Use
//!,/** ... */, and//!<syntax for doxygen comments (which will end up being compiled into the API Reference), see Doxygen for details on doxygen.File Comments¶
Start each file with license boilerplate. e.g., for file
common.hhauthored by John Doe:Note on copyright: it is shared among the writers of the particular file, but chances are that in most cases, at least part of each new file contains ideas or even copied-and-pasted snippets from other files. Give the authors of those files also shared copyright.
File comments describe the contents of a file. If a file declares, implements, or tests exactly one abstraction that is documented by a comment at the point of declaration, file comments are not required. All other files must have file comments.
Every file should contain GPL boilerplate.
Do not duplicate comments in both the
.hhand the .cc. Duplicated comments diverge.Class Comments¶
Every non-obvious class declaration should have an accompanying comment that describes what it is for and how it should be used.
The class comment should provide the reader with enough information to know how and when to use the class, as well as any additional considerations necessary to correctly use the class. Document the assumptions the class makes, if any. If an instance of the class can be accessed by multiple threads, take extra care to document the rules and invariants surrounding multithreaded use.
The class comment is often a good place for a small example code snippet demonstrating a simple and focused usage of the class.
When sufficiently separated (e.g.
.hhand.ccfiles), comments describing the use of the class should go together with its interface definition; comments about the class operation and implementation should accompany the interface definition of the class’s methods.Function Comments¶
Declaration comments describe use of the function; comments at the definition of a function describe operation.
Function Declarations¶
Every function declaration should have comments immediately preceding it that describe what the function does and how to use it. These comments should be descriptive (“Opens the file”) rather than imperative (“Open the file”); the comment describes the function, it does not tell the function what to do. In general, these comments do not describe how the function performs its task. Instead, that should be left to comments in the function definition.
Types of things to mention in comments at the function declaration:
What the inputs and outputs are.
For class member functions: whether the object remembers reference arguments beyond the duration of the method call, and whether it will free them or not.
If the function allocates memory that the caller must free.
Whether any of the arguments can be a null pointer.
If there are any performance implications of how a function is used.
If the function is re-entrant. What are its synchronisation assumptions?
Here is an example:
However, do not be unnecessarily verbose or state the completely obvious.
When documenting function overrides, focus on the specifics of the override itself, rather than repeating the comment from the overridden function. In many of these cases, the override needs no additional documentation and thus only brief comments are required.
When commenting constructors and destructors, remember that the person reading your code knows what constructors and destructors are for, so comments that just say something like “destroys this object” are not useful. Document what constructors do with their arguments (for example, if they take ownership of pointers), and what cleanup the destructor does. If this is trivial, just name it (
default constructor,move constructor,destructoretc).Function Definitions¶
If there is anything tricky about how a function does its job, the function definition should have an explanatory comment. For example, in the definition comment you might describe any coding tricks you use, give an overview of the steps you go through, or explain why you chose to implement the function in the way you did rather than using a viable alternative. For instance, you might mention why it must acquire a lock for the first half of the function but why it is not needed for the second half.
Note you should not just repeat the comments given with the function declaration, in the
.hhfile or wherever. It’s okay to recapitulate briefly what the function does, but the focus of the comments should be on how it does it.Variable Comments¶
In general the actual name of the variable should be descriptive enough to give a good idea of what the variable is used for, but we require a short description for the API documentation.
Class Data Members¶
The purpose of each class data member (also called an instance variable or member variable) must be clear. If there are any invariants (special values, relationships between members, lifetime requirements) not clearly expressed by the type and name, they must be commented. However, if the type and name suffice (
int nb_events;), a brief “number of events” is a sufficient comment:Global Variables¶
All global variables should have a comment describing what they are, what they are used for, and (if unclear) why it needs to be global. For example:
Implementation Comments¶
In your implementation you should have comments in tricky, non-obvious, interesting, or important parts of your code. Explanatory Comments
Tricky or complicated code blocks should have comments before them. Example:
Line Comments¶
Also, lines that are non-obvious should get a comment at the end of the line. These end-of-line comments should be separated from the code by at least one space. Example:
Note that there are both comments that describe what the code is doing, and comments that mention that an error has already been logged when the function returns.
If you have several comments on subsequent lines, it can often be more readable to line them up:
Self-describing code doesn’t need a comment. The comment from the example above would be obvious:
Punctuation, Spelling and Grammar¶
Pay attention to punctuation, spelling, and grammar; it is easier to read well-written comments than badly written ones.
Comments should be as readable as narrative text, with proper capitalisation and punctuation. In many cases, complete sentences are more readable than sentence fragments. Shorter comments, such as comments at the end of a line of code, can sometimes be less formal, but you should be consistent with your style.
Although it can be frustrating to have a code reviewer point out that you are using a comma when you should be using a semicolon, it is very important that source code maintain a high level of clarity and readability. Proper punctuation, spelling, and grammar help with that goal.
TODOComments¶Use
TODOcomments for code that is temporary, a short-term solution, or good-enough but not perfect.TODOs should include the stringTODOin all caps, followed by the name, e-mail address, Phabricator task number or other identifier of the person or issue with the best context about the problem referenced by theTODO. The main purpose is to have a consistentTODOthat can be searched to find out how to get more details upon request. ATODOis not a commitment that the person referenced will fix the problem. Thus when you create aTODOwith a name, it is almost always your name that is given.If your
TODOis of the form “At a future date do something” make sure that you either include a very specific date (“Fix by November 2005”) or a very specific event (“Remove this code when all clients can handle XML responses.”).Deprecation Comments¶
Mark deprecated interface points with
DEPRECATEDcomments.You can mark an interface as deprecated by writing a comment containing the word
DEPRECATEDin all caps. The comment goes either before the declaration of the interface or on the same line as the declaration.After the word
DEPRECATED, write your name, e-mail address, or other identifier in parentheses.A deprecation comment must include simple, clear directions for people to fix their call sites. In C++, you can implement a deprecated function as an inline function that calls the new interface point.
Marking an interface point
DEPRECATEDwill not magically cause any call sites to change. If you want people to actually stop using the deprecated facility, you will have to fix the call sites yourself or recruit a crew to help you.New code should not contain calls to deprecated interface points. Use the new interface point instead. If you cannot understand the directions, find the person who created the deprecation and ask them for help using the new interface point.